Yesterday Moonshot AI dropped Kimi K2.7 Code on Hugging Face: a 1-trillion-parameter Mixture-of-Experts coding model (32B active) with a 256K context window, open weights under a Modified MIT license.
If you read our Claude Fable 5 piece, this is the same logic running in reverse. With Fable 5, the capability was proven and the price was the risk. With K2.7 Code, the price is trivial and the capability is the open question. The model is one day old, no third party has benchmarked it, and Moonshot's own numbers put it behind the frontier. Both situations end in the same posture: run a cheap, reversible experiment inside the coding harness you already use.
There is one twist that makes this experiment more interesting than a simple swap. At $0.95 per million input tokens and $4.00 per million output, K2.7 Code costs about a tenth of Claude Fable 5 on input and a twelfth on output. That is cheap enough to give it a different job: working alongside your SOTA model, taking the routine fan-out work while the expensive model keeps the hard parts.
K2.7 Code is on Token Station as kimi/kimi-k2.7-code, at Moonshot's list price with zero markup, and your $1 signup credit covers a lot of it.
What we know (and what we don't)
From the model card:
- Built for coding agents. It is a coding-focused successor to Kimi K2.6, tuned for long-horizon software engineering: interleaved thinking, multi-step tool calls, MCP support, and reasoning preserved across turns.
- About 30% fewer thinking tokens than K2.6 at higher coding scores, which matters when you pay per output token.
- 1T total parameters, 32B active, 384 experts, native INT4 support, plus a 400M-parameter vision encoder for image input.
- Open weights, Modified MIT. You can download the whole thing and serve it yourself with vLLM or SGLang.
And the honest part. Moonshot published its own comparison against the frontier, and K2.7 Code loses:
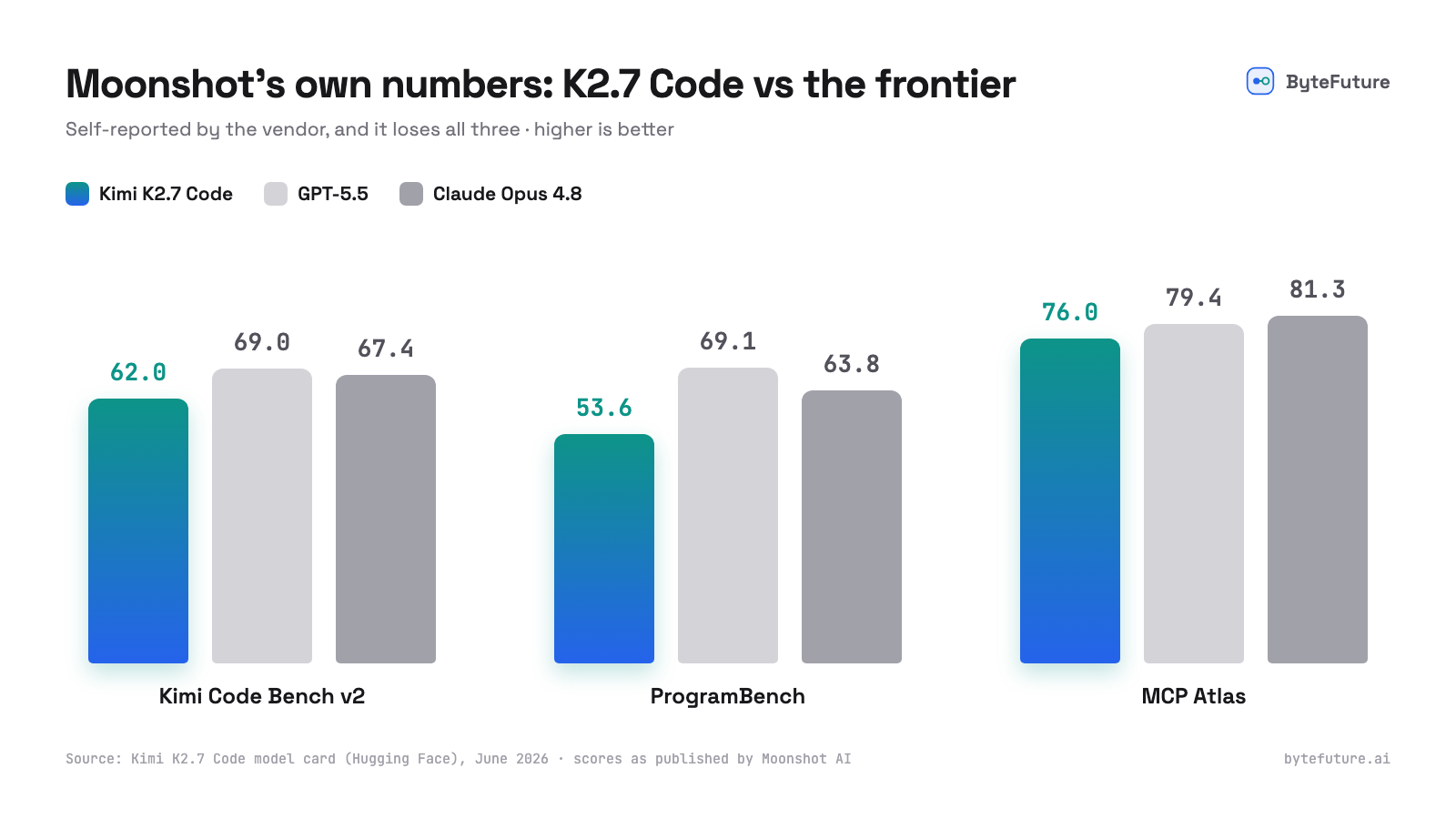
A vendor publishing benchmarks where its model loses is a good sign for the numbers' honesty, and the gaps are not embarrassing: roughly 7 points behind GPT-5.5 on Moonshot's coding bench, closer on tool use. The previous Kimi release (K2.6) is currently the best open-weights model on the Artificial Analysis Intelligence Index. What nobody knows yet is how K2.7 Code behaves on your codebase, in your harness, over a long agentic session. That is the unknown this experiment resolves.
One disambiguation, in the same spirit as our Grok Build article: K2.7 Code the model is optimized for Moonshot's own Kimi Code CLI, their coding harness. You do not need that CLI. The model speaks OpenAI- and Anthropic-compatible APIs, and Token Station translates whatever your existing harness sends.
The price: a rounding error next to the frontier
All of these are live on Token Station at the providers' list prices:
| Model | Input / 1M | Output / 1M | Context |
|---|---|---|---|
kimi/kimi-k2.7-code | $0.95 | $4.00 | 256K |
xai/grok-build-0.1 | $1.00 | $2.00 | 256K |
anthropic/claude-sonnet-4-6 | $3.00 | $15.00 | 1M |
anthropic/claude-opus-4-8 | $5.00 | $25.00 | 1M |
openai/gpt-5.5 | $5.00 | $30.00 | 1M |
anthropic/claude-fable-5 | $10.00 | $50.00 | 1M |
The $1 signup credit buys roughly 1 million input tokens or 250K output tokens at K2.7 Code prices. Where the same credit barely covers a few Fable 5 prompts, here it covers a real evaluation. The downside risk of this experiment rounds to zero. And your first top-up adds up to $50 in bonus credit, which at K2.7 Code prices is weeks of evaluation.
The real experiment: share the work
Coding agents already split their work into tiers. There is the main loop, where planning and hard reasoning happen, and there is the fan-out: subagents reading files, running searches, executing tests, summarizing results. The fan-out burns most of the tokens and needs the least brilliance.
That split is exactly where a $4-per-million model earns a place next to a $50-per-million one. Keep Fable 5 or Opus 4.8 in the driver's seat and hand the routine work to K2.7 Code. If Moonshot's numbers hold up in practice, the quality drop on delegated tasks is small and the cost drop is more than 10x on every delegated token.
What you need
- A Token Station account (sign up free; $1 in credit, no card, no Moonshot account needed)
- Your Token Station API key (starts with
gw-) - Claude Code, Codex, or OpenClaw installed
Claude Code setup: the two-tier split
Claude Code exposes its model tiers as environment variables, which makes it the cleanest place to run the share-the-work experiment. Reserve the Opus slot for Claude Fable 5 and give everything else to the workhorse:
# Token Station endpoint + auth
export ANTHROPIC_BASE_URL="https://models.bytefuture.ai"
export ANTHROPIC_AUTH_TOKEN="gw-YOUR_TOKEN_STATION_KEY"
# Top tier: Fable 5 takes the genuinely hard problems
export ANTHROPIC_DEFAULT_OPUS_MODEL="anthropic/claude-fable-5"
# Everything else runs on the workhorse
export ANTHROPIC_DEFAULT_SONNET_MODEL="kimi/kimi-k2.7-code"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="kimi/kimi-k2.7-code"
export CLAUDE_CODE_SUBAGENT_MODEL="kimi/kimi-k2.7-code"
claudeAn ordinary session now runs K2.7 Code end to end: the main loop, every subagent, every background search, all billing at $4 per million output instead of $50. When a problem actually needs frontier judgment, escalate with /model opus and Fable 5 takes over; drop back down when the hard part is done. The expensive model becomes what it should be at that price, a specialist you call in.
Swap anthropic/claude-fable-5 for anthropic/claude-opus-4-8 in the Opus slot if Fable 5's price makes you wince; the escalation pattern works at any tier.
Codex setup
Codex runs one model per session, but its profiles give you the same split at the invocation level: make the workhorse the default and keep a named escalation profile for Fable 5.
mkdir -p ~/.codex
cat > ~/.codex/config.toml <<'EOF'
# Default: the workhorse
model = "kimi/kimi-k2.7-code"
model_provider = "token_station"
[model_providers.token_station]
name = "token_station"
base_url = "https://models.bytefuture.ai/v1"
env_key = "TOKEN_STATION_API_KEY"
wire_api = "responses"
# Escalation: Fable 5 on demand
[profiles.deep]
model = "anthropic/claude-fable-5"
EOF
export TOKEN_STATION_API_KEY="gw-YOUR_TOKEN_STATION_KEY"
codex # routine work on K2.7 Code
codex --profile deep # hard problems on Fable 5Day to day you launch plain codex and pay workhorse rates. When a task deserves the frontier model, codex --profile deep brings in Fable 5 for that invocation only. Nothing else in the config moves.
OpenClaw setup
OpenClaw makes the split a first-class setting. Sub-agents inherit the caller's model unless agents.defaults.subagents.model says otherwise (docs), so Fable 5 can drive while every spawned sub-agent runs on K2.7 Code:
{
"models": {
"mode": "merge",
"providers": {
"token-station": {
"baseUrl": "https://models.bytefuture.ai/v1",
"apiKey": "${TOKEN_STATION_API_KEY}",
"api": "anthropic-messages",
"models": [
{
"id": "anthropic/claude-fable-5",
"name": "Claude Fable 5 (Token Station)",
"contextWindow": 1000000,
"maxTokens": 128000
},
{
"id": "kimi/kimi-k2.7-code",
"name": "Kimi K2.7 Code (Token Station)",
"contextWindow": 256000,
"maxTokens": 32768
}
]
}
}
},
"agents": {
"defaults": {
"model": { "primary": "token-station/anthropic/claude-fable-5" },
"subagents": { "model": "token-station/kimi/kimi-k2.7-code" }
}
}
}The main agent keeps frontier judgment; the parallel fan-out (the part that burns tokens) bills at workhorse rates. To run the whole thing on K2.7 Code instead, point agents.defaults.model.primary at it; both models sit behind the same key either way.
Quirks worth knowing
- Thinking is always on. K2.7 Code reasons before answering and carries that reasoning across turns; you cannot turn it off. Budget for reasoning tokens in the output bill, softened by the 30% reduction over K2.6.
- 256K context. Generous, but a quarter of the 1M window on frontier Claude and GPT models. Long agentic sessions will compact sooner.
- It has a home-team harness. Moonshot tunes it for the Kimi Code CLI, so expect occasional rough edges elsewhere. Token Station's tool and parameter name translation handles the wire-level mismatches.
- The exit path goes both ways. If the experiment fails, delete the config. If it succeeds, the weights are Modified MIT on Hugging Face: you can eventually serve the exact same model on your own hardware. A cloud experiment that can graduate to self-hosting is the hybrid-inference story in miniature.
Run the experiment
Give K2.7 Code the work your expensive model is overqualified for: subagent searches, test runs, boilerplate, summaries. Watch for a week where it holds up and where it drops the ball, then settle the split accordingly. The same Token Station key runs anthropic/claude-fable-5, anthropic/claude-opus-4-8, and kimi/kimi-k2.7-code side by side, so the comparison is built in.
Sign up at models.bytefuture.ai ($1 in free credit, no card; up to $50 bonus on your first top-up) and find out whether a one-day-old open-weights model can carry half your agent's workload at a tenth of the price.