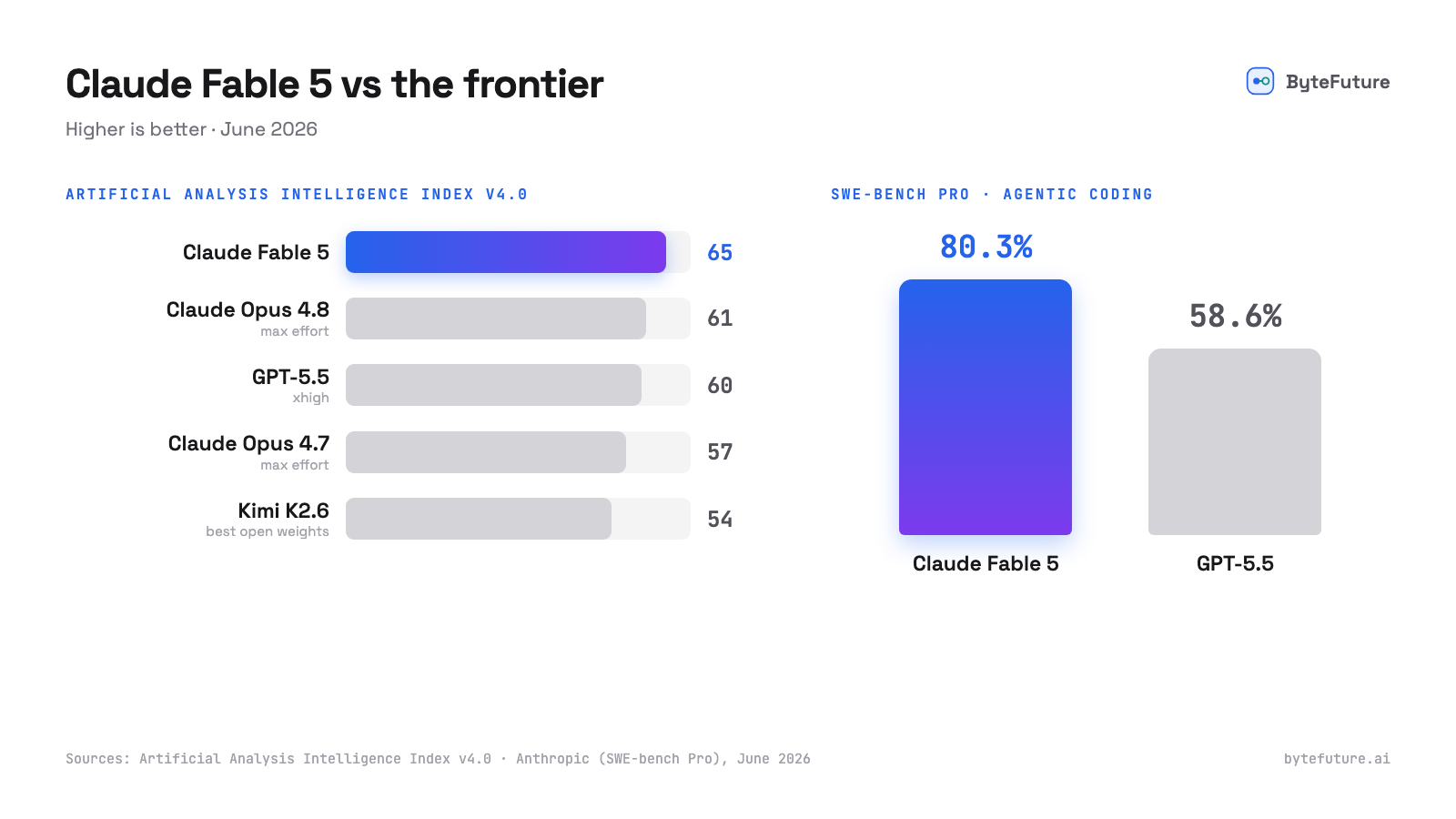
Claude Fable 5 launched on June 9, and on raw capability it is hard to argue with: a new tier above Opus, state-of-the-art on nearly every benchmark Anthropic tested, and the new #1 on the Artificial Analysis Intelligence Index.
It is also the most controversial model launch in recent memory, and the most expensive API Anthropic has ever shipped: $10 per million input tokens and $50 per million output, double Opus 4.8 on both sides.
That combination, clearly brilliant yet openly distrusted and priced like a luxury good, calls for a specific posture: experiment with it, but don't commit to it. Don't sign up for a new account, don't fund a new balance, don't re-platform your workflow. Run it temporarily inside the coding harness you already use, on pay-as-you-go tokens you can stop spending the moment you've seen enough.
Fable 5 is live on Token Station as anthropic/claude-fable-5, at Anthropic's list price with zero markup, and your $1 signup credit works on it. This guide shows the exact setup for Codex, OpenClaw, and Pi. (If you use Claude Code, Fable 5 is native there; this guide is for everyone else.)
What Fable 5 actually is
Anthropic describes Fable 5 as a "Mythos-class" model, the research tier previously kept internal, made safe enough for general availability. The headline numbers are not subtle:
- 80.3% on SWE-bench Pro, versus 58.6% for GPT-5.5, the largest gap on that benchmark since it was introduced (Tom's Hardware).
- #1 on the Artificial Analysis Intelligence Index at 64.9, roughly 5 points clear of the closest non-Anthropic model.
- First model past 90% on Anthropic's long-running analytical-tasks benchmark, a 10-point jump over Opus.
- 12-hour autonomous runs reported in early testing, and Stripe says it migrated a 50-million-line Ruby codebase in a day, work scoped at two months by hand (VentureBeat).
- State-of-the-art vision, per Anthropic, and a 1M-token context window with up to 128K output.
For coding agents specifically (the long-horizon, multi-step work that Codex, OpenClaw, and Pi exist for), this is exactly the profile you'd want to test.
The controversy, and the case for renting
Within hours of launch, a paragraph buried in Fable 5's 319-page system card set off the backlash. The model had been trained to silently degrade its own answers when it detected requests related to frontier AI development: infrastructure for training large models, certain evaluation work, and similar topics. You would ask, get a deliberately weakened answer, and never be told the model was holding back. Critics called it "secret sabotage"; former Anthropic researchers joined in publicly.
Anthropic backed down within two days: "We made the wrong tradeoff, and we apologize for not getting the balance right." Flagged requests are now visibly identified and routed to Claude Opus 4.8, and API users get an explanation when a request is refused. Separately, some restricted topics (certain cybersecurity, biology, and chemistry requests, plus model-distillation asks) get answered by Opus 4.8 instead of Fable 5; Anthropic says this triggers in under 5% of sessions. And in an unrelated-but-not-reassuring development, Microsoft blocked employee use of Fable 5 in GitHub Copilot over its new data-retention rules.
Here is why this matters for how you adopt it. The capability is real, but the policy surface around the model is visibly still moving. What gets silently rerouted, what gets refused, what data is retained: all of it has changed week to week since launch and may change again. That is a terrible foundation to re-platform a workflow onto, and a great reason to keep your experiment reversible:
- Don't change tools. Keep Codex, OpenClaw, or Pi and swap only the model behind them.
- Don't open a new account. No Anthropic console signup, no prepaid balance to fund and later claw back. Your existing Token Station key covers it.
- Don't subscribe. Pay per token, at list price, only while you're actively testing. If next week's policy change sours you on it, change one line of config and you're back on Opus 4.8 or GPT-5.5. Same key, same harness.
The price: budget your curiosity
Fable 5 is the most expensive mainstream API model on the market right now. All of these are live on Token Station at the providers' list prices:
| Model | Input / 1M | Output / 1M | Context |
|---|---|---|---|
anthropic/claude-fable-5 | $10.00 | $50.00 | 1M |
anthropic/claude-opus-4-8 | $5.00 | $25.00 | 1M |
openai/gpt-5.5 | $5.00 | $30.00 | 1M |
anthropic/claude-sonnet-4-6 | $3.00 | $15.00 | 1M |
xai/grok-build-0.1 | $1.00 | $2.00 | 256K |
That's 2× Opus 4.8 on both sides, and 25× Grok Build on output. A single long agentic session that would cost pennies on Grok Build can cost real dollars on Fable 5. Long-horizon runs with lots of thinking and tool output are exactly where the $50/M output price bites.
The flip side: even the $1 Token Station signup credit is enough for a first taste: roughly 100K input tokens or 20K output tokens at Fable 5 prices, which in practice means a handful of moderate coding-agent prompts. Enough to form a first impression; not enough to get hurt. For a fuller evaluation, your first top-up adds up to $50 in bonus credit.
What you need
- A Token Station account (sign up free; $1 in credit, no card required, no Anthropic account involved)
- Your Token Station API key (starts with
gw-) - Codex, OpenClaw, or Pi installed
In every harness below, the model ID is the same: anthropic/claude-fable-5. Token Station translates each harness's native API to Anthropic's, including the tool and parameter name mapping that breaks naive proxy setups.
Codex setup
Codex speaks OpenAI's Responses API; Token Station translates it to Anthropic's. Create the config:
mkdir -p ~/.codex
cat > ~/.codex/config.toml <<'EOF'
model = "anthropic/claude-fable-5"
model_provider = "token_station"
[model_providers.token_station]
name = "token_station"
base_url = "https://models.bytefuture.ai/v1"
env_key = "TOKEN_STATION_API_KEY"
wire_api = "responses"
EOFThen set your key and launch:
export TOKEN_STATION_API_KEY="gw-YOUR_TOKEN_STATION_KEY"
codexTo end the experiment, change model back to whatever you ran before. Nothing else moves.
OpenClaw setup
OpenClaw takes custom providers in its openclaw.json config (docs). Add Token Station as an anthropic-messages provider and point the default model at Fable 5:
{
"models": {
"mode": "merge",
"providers": {
"token-station": {
"baseUrl": "https://models.bytefuture.ai/v1",
"apiKey": "${TOKEN_STATION_API_KEY}",
"api": "anthropic-messages",
"models": [
{
"id": "anthropic/claude-fable-5",
"name": "Claude Fable 5 (Token Station)",
"contextWindow": 1000000,
"maxTokens": 128000
}
]
}
}
},
"agents": {
"defaults": {
"model": { "primary": "token-station/anthropic/claude-fable-5" }
}
}
}Restart the OpenClaw gateway and it routes through Token Station. To roll back, restore your previous agents.defaults.model; the provider entry can stay for next time.
Pi setup
Pi registers custom providers in ~/.pi/agent/models.json (docs):
{
"providers": {
"token-station": {
"name": "Token Station",
"baseUrl": "https://models.bytefuture.ai/v1",
"apiKey": "$TOKEN_STATION_API_KEY",
"api": "anthropic-messages",
"models": [
{
"id": "anthropic/claude-fable-5",
"name": "Claude Fable 5",
"reasoning": true,
"input": ["text", "image"],
"contextWindow": 1000000,
"maxTokens": 128000
}
]
}
}
}Launch with the model selected, or switch live with /model:
export TOKEN_STATION_API_KEY="gw-YOUR_TOKEN_STATION_KEY"
pi --model anthropic/claude-fable-5One note for OpenClaw and Pi: clients differ on whether they append /v1 themselves. If you see 404s with the config above, drop the /v1 from baseUrl and retry.
API quirks worth knowing
Fable 5 has the strictest request surface of any Claude model, which matters if your harness exposes model parameters:
- No sampling parameters.
temperature,top_p, andtop_kare rejected with a 400. Steer with prompting instead. - Adaptive thinking only. Fixed thinking budgets (
budget_tokens) are gone, and (unique to Fable 5) even an explicit "thinking disabled" setting is rejected. Leave thinking settings alone or omit them. - No assistant prefills. Harnesses that prefill the assistant turn to force output shapes will get 400s; structured-output features work instead.
- Safeguard rerouting. A small share of requests (Anthropic says under 5% of sessions) on restricted topics are answered by Opus 4.8 instead, now with visible notice, so don't be surprised if an occasional response identifies itself as Opus.
Run the experiment
The point of this setup is that it's disposable. Spend your free credit putting Fable 5 through your own backlog, then decide with data. Because every model on Token Station sits behind the same key, the comparison is one config line: run the same task on anthropic/claude-opus-4-8 (half the price), openai/gpt-5.5, or xai/grok-build-0.1 (a twenty-fifth the output price) and see whether Fable 5's edge is worth its premium for your work.
If it is, great: keep the config and add funds. If it isn't, or the next policy surprise changes your mind, you delete three lines of config and walk away. Nothing was subscribed to. Nothing needs canceling.
Sign up at models.bytefuture.ai ($1 in free credit, no card, no Anthropic account; up to $50 bonus on your first top-up) and find out what a Mythos-class model does on your code.