昨天 Moonshot AI 在 Hugging Face 上发布了 Kimi K2.7 Code:一个 1 万亿参数的混合专家(MoE)编码模型(激活参数 32B),上下文窗口 256K,权重以 Modified MIT 许可证开放。
如果你读过我们那篇 Claude Fable 5 的文章,这次的逻辑正好反过来。Fable 5 的能力已被验证,风险在于价格。而 K2.7 Code 的价格微不足道,能力才是悬而未决的问题。这个模型才发布一天,还没有任何第三方对它做过基准测试,连 Moonshot 自己公布的数字都把它排在前沿模型之后。但这两种情形最终都指向同一种做法:在你已经在用的编码工具里,跑一个便宜且可随时回退的实验。
有一点让这个实验比单纯的替换更有意思。在 每百万输入 token 0.95 美元、每百万输出 token 4.00 美元 的价格下,K2.7 Code 的输入价格约为 Claude Fable 5 的十分之一,输出价格约为十二分之一。这便宜到足以让它担任另一种角色:和你的 SOTA 模型并肩工作,承担那些常规的分发任务,而把难啃的部分留给昂贵的模型。
K2.7 Code 已经上线 Token Station,模型 ID 为 kimi/kimi-k2.7-code,按 Moonshot 的标价、零加价提供,而你的 1 美元注册赠金 足够用上很久。
我们已知的(以及未知的)
来自模型卡:
- 为编码 agent 而生。它是 Kimi K2.6 面向编码的后继版本,针对长周期的软件工程做了调优:交错思考、多步工具调用、MCP 支持,以及跨轮次保留的推理过程。
- 思考 token 比 K2.6 少约 30%,同时编码得分更高,这在按输出 token 计费时很关键。
- 总参数 1T,激活参数 32B,384 个专家,原生支持 INT4,外加一个 400M 参数的视觉编码器用于图像输入。
- 开放权重,Modified MIT 许可。你可以把整个模型下载下来,用 vLLM 或 SGLang 自行部署。
还有坦诚的一面。Moonshot 公布了它和前沿模型的对比,而 K2.7 Code 落了下风:
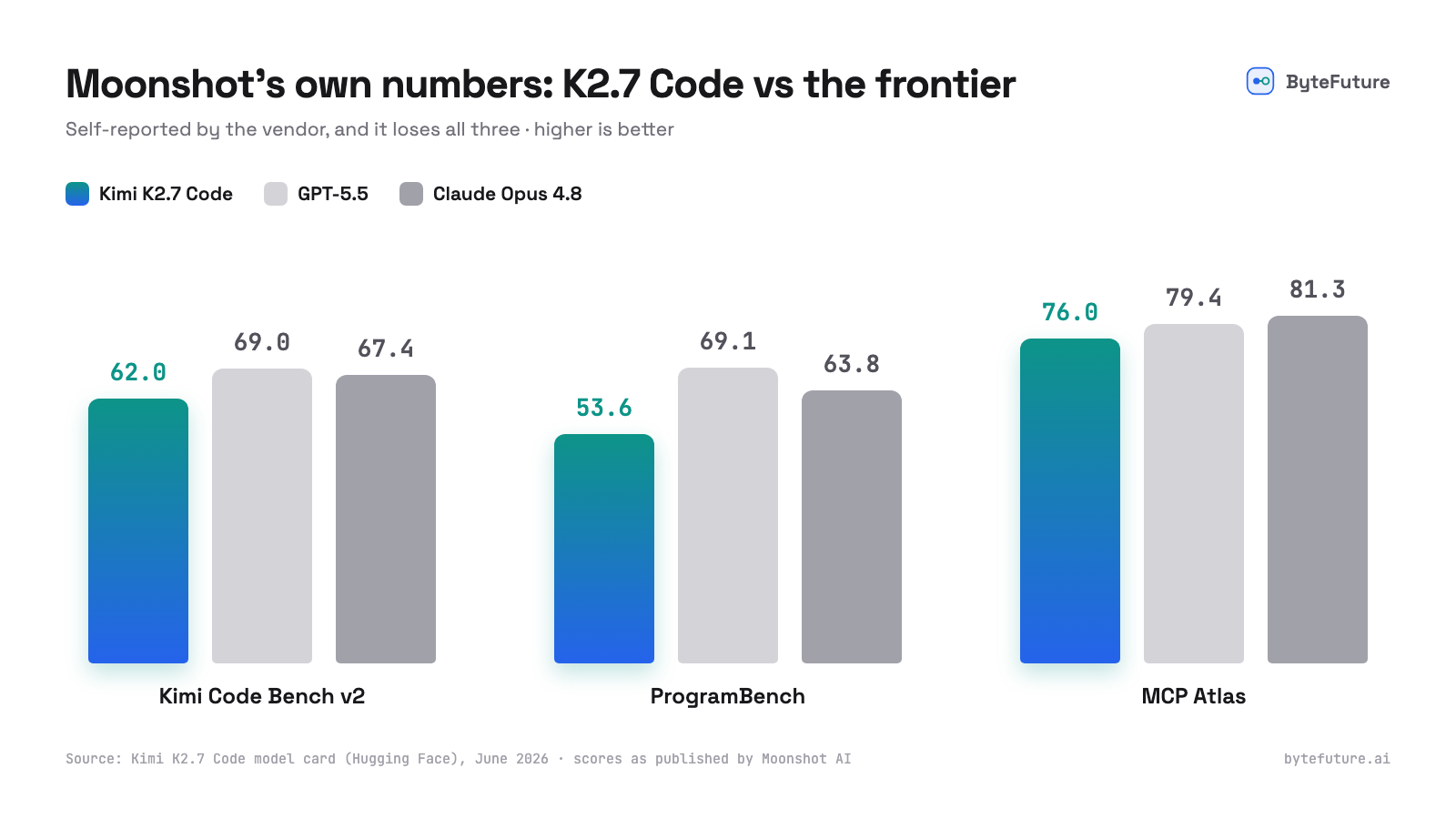
一家厂商公布自己模型落败的基准,是这些数字诚实可信的好迹象,而且差距并不难看:在 Moonshot 的编码基准上比 GPT-5.5 落后约 7 分,在工具使用上更接近。上一代 Kimi(K2.6)目前是 Artificial Analysis Intelligence Index 上最强的开放权重模型。眼下没人知道的是,K2.7 Code 在你的代码库、你的工具里、经过一段长时间的 agent 会话之后表现如何。这正是这个实验要回答的未知数。
有一点需要厘清,和我们那篇 Grok Build 文章的思路一致:K2.7 Code 这个模型是针对 Moonshot 自家的 Kimi Code CLI(他们的编码工具)做优化的。但你并不需要那个 CLI。这个模型支持 OpenAI 和 Anthropic 兼容的 API,而 Token Station 会把你现有工具发出的请求翻译成它能理解的格式。
价格:在前沿模型面前几乎可以忽略不计
下面这些模型都已在 Token Station 上线,按各家厂商的标价提供:
| 模型 | 输入 / 1M | 输出 / 1M | 上下文 |
|---|---|---|---|
kimi/kimi-k2.7-code | $0.95 | $4.00 | 256K |
xai/grok-build-0.1 | $1.00 | $2.00 | 256K |
anthropic/claude-sonnet-4-6 | $3.00 | $15.00 | 1M |
anthropic/claude-opus-4-8 | $5.00 | $25.00 | 1M |
openai/gpt-5.5 | $5.00 | $30.00 | 1M |
anthropic/claude-fable-5 | $10.00 | $50.00 | 1M |
按 K2.7 Code 的价格,1 美元注册赠金大约能买 100 万个输入 token 或 25 万个输出 token。同样一笔赠金,用 Fable 5 只够跑几次提示,用它却能撑起一次真正的评测。这个实验的下行风险几乎为零。而且首次充值最高还能再获得 50 美元赠送额度,按 K2.7 Code 的价格足够用上好几周。
真正的实验:分担工作
编码 agent 早就把工作分成了不同层级。一边是主循环,负责规划和高难度推理;另一边是分发任务:子 agent 读取文件、执行搜索、运行测试、汇总结果。分发任务消耗了绝大部分 token,却最不需要聪明才智。
正是在这种分工下,一个每百万 4 美元的模型才有理由和每百万 50 美元的模型并肩而立。让 Fable 5 或 Opus 4.8 坐镇主驾,把常规工作交给 K2.7 Code。如果 Moonshot 的数字在实际中站得住脚,那么委派任务上的质量下降很小,而每个被委派的 token 成本下降都超过 10 倍。
你需要准备什么
- 一个 Token Station 账号(免费注册;1 美元赠金,无需信用卡,也不需要 Moonshot 账号)
- 你的 Token Station API 密钥(以
gw-开头) - 已安装 Claude Code、Codex 或 OpenClaw
Claude Code 配置:两层分工
Claude Code 把它的模型层级以环境变量的形式暴露出来,因此它是跑这个分担工作实验最干净利落的地方。把 Opus 这一档留给 Claude Fable 5,其余全部交给这匹主力模型:
# Token Station endpoint + auth
export ANTHROPIC_BASE_URL="https://models.bytefuture.ai"
export ANTHROPIC_AUTH_TOKEN="gw-YOUR_TOKEN_STATION_KEY"
# Top tier: Fable 5 takes the genuinely hard problems
export ANTHROPIC_DEFAULT_OPUS_MODEL="anthropic/claude-fable-5"
# Everything else runs on the workhorse
export ANTHROPIC_DEFAULT_SONNET_MODEL="kimi/kimi-k2.7-code"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="kimi/kimi-k2.7-code"
export CLAUDE_CODE_SUBAGENT_MODEL="kimi/kimi-k2.7-code"
claude现在一次普通的会话会全程跑在 K2.7 Code 上:主循环、每个子 agent、每次后台搜索,全部按每百万输出 4 美元计费,而不是 50 美元。当某个问题确实需要前沿级判断时,用 /model opus 升级,Fable 5 就会接手;难啃的部分搞定后再降回来。这样昂贵的模型就回到了它在那个价位上本该扮演的角色:一位被你请来的专家。
如果 Fable 5 的价格让你心疼,就把 Opus 档里的 anthropic/claude-fable-5 换成 anthropic/claude-opus-4-8;这套升级模式在任何档位都适用。
Codex 配置
Codex 每次会话只跑一个模型,但它的 profiles 能在调用层面实现同样的分工:把主力模型设为默认,再为 Fable 5 单独保留一个命名的升级 profile。
mkdir -p ~/.codex
cat > ~/.codex/config.toml <<'EOF'
# Default: the workhorse
model = "kimi/kimi-k2.7-code"
model_provider = "token_station"
[model_providers.token_station]
name = "token_station"
base_url = "https://models.bytefuture.ai/v1"
env_key = "TOKEN_STATION_API_KEY"
wire_api = "responses"
# Escalation: Fable 5 on demand
[profiles.deep]
model = "anthropic/claude-fable-5"
EOF
export TOKEN_STATION_API_KEY="gw-YOUR_TOKEN_STATION_KEY"
codex # routine work on K2.7 Code
codex --profile deep # hard problems on Fable 5日常你直接运行 codex,按主力模型的价格付费。当某个任务值得动用前沿模型时,codex --profile deep 仅在这一次调用中请出 Fable 5。配置里其他部分一概不动。
OpenClaw 配置
OpenClaw 把这种分工做成了一等公民的设置。除非 agents.defaults.subagents.model 另有指定,否则子 agent 会继承调用方的模型(文档),因此可以让 Fable 5 坐镇主驾,而每个派生出来的子 agent 都跑在 K2.7 Code 上:
{
"models": {
"mode": "merge",
"providers": {
"token-station": {
"baseUrl": "https://models.bytefuture.ai/v1",
"apiKey": "${TOKEN_STATION_API_KEY}",
"api": "anthropic-messages",
"models": [
{
"id": "anthropic/claude-fable-5",
"name": "Claude Fable 5 (Token Station)",
"contextWindow": 1000000,
"maxTokens": 128000
},
{
"id": "kimi/kimi-k2.7-code",
"name": "Kimi K2.7 Code (Token Station)",
"contextWindow": 256000,
"maxTokens": 32768
}
]
}
}
},
"agents": {
"defaults": {
"model": { "primary": "token-station/anthropic/claude-fable-5" },
"subagents": { "model": "token-station/kimi/kimi-k2.7-code" }
}
}
}主 agent 保留前沿级判断;并行的分发任务(也就是烧 token 的那部分)按主力模型的价格计费。如果想让整套流程全部跑在 K2.7 Code 上,就把 agents.defaults.model.primary 指向它;无论哪种方式,两个模型都在同一个密钥背后。
值得了解的几个特性
- 思考始终开启。K2.7 Code 在回答前会先推理,并把推理过程带入后续轮次;你无法关闭它。要把推理 token 算进输出账单,好在相比 K2.6 减少了 30%,压力会小一些。
- 256K 上下文。已经很慷慨,但只有前沿 Claude 和 GPT 模型 1M 窗口的四分之一。较长的 agent 会话会更早触发压缩。
- 它有自己的主场工具。Moonshot 是针对 Kimi Code CLI 调优的,所以在别处偶尔会遇到一些粗糙之处。Token Station 对工具和参数名的翻译会处理掉协议层面的不匹配。
- 退出之路两头都通。如果实验失败,删掉配置就行。如果成功,权重以 Modified MIT 许可放在 Hugging Face 上:你最终可以在自己的硬件上部署一模一样的模型。一个能够升级为自托管的云端实验,正是混合推理故事的缩影。
开始这个实验
把那些你那昂贵模型大材小用的活儿交给 K2.7 Code:子 agent 搜索、测试运行、样板代码、内容汇总。观察一周,看它在哪里站得住、在哪里掉链子,然后据此确定分工。同一个 Token Station 密钥能并排跑 anthropic/claude-fable-5、anthropic/claude-opus-4-8 和 kimi/kimi-k2.7-code,所以对比是天然内置的。
到 models.bytefuture.ai 注册(1 美元免费赠金,无需信用卡;首次充值最高再送 50 美元),亲自看看一个才发布一天的开放权重模型,能否以十分之一的价格扛起你 agent 一半的工作量。