어제 Moonshot AI가 Hugging Face에 Kimi K2.7 Code를 공개했습니다. 1조 파라미터의 Mixture-of-Experts 코딩 모델(활성 32B)로, 256K 컨텍스트 윈도를 갖추고 Modified MIT 라이선스로 가중치가 공개됩니다.
저희 Claude Fable 5 글을 읽으셨다면, 이번에는 그 논리가 정반대로 작동한다는 것을 아실 겁니다. Fable 5는 성능이 입증되어 있었고, 위험은 가격이었습니다. K2.7 Code는 가격이 미미하고, 성능이야말로 미결의 문제입니다. 이 모델은 공개된 지 하루밖에 안 되었고, 제3자의 벤치마크도 아직 없으며, Moonshot 자신의 수치마저 이 모델을 프런티어 뒤에 둡니다. 두 상황 모두 결국 같은 태도로 귀결됩니다. 이미 쓰고 있는 코딩 환경 안에서 저렴하고 언제든 되돌릴 수 있는 실험을 돌려 보는 것입니다.
이 실험을 단순한 교체 이상으로 흥미롭게 만드는 점이 하나 있습니다. 입력 100만 토큰당 0.95달러, 출력 100만 토큰당 4.00달러로, K2.7 Code는 입력에서 Claude Fable 5의 약 10분의 1, 출력에서는 12분의 1 비용입니다. 이는 다른 역할을 맡길 만큼 저렴하다는 뜻입니다. 여러분의 SOTA 모델과 나란히 일하며, 비싼 모델이 어려운 부분을 맡는 동안 일상적인 팬아웃 작업을 가져가는 것이죠.
K2.7 Code는 Token Station에서 kimi/kimi-k2.7-code로 이용할 수 있으며, Moonshot의 정가 그대로 추가 마진 없이 제공됩니다. 1달러의 가입 크레딧이면 상당히 오래 쓸 수 있습니다.
우리가 아는 것(그리고 모르는 것)
모델 카드에서:
- 코딩 에이전트를 위해 만들어졌다. Kimi K2.6의 코딩 특화 후속 모델로, 장기 소프트웨어 엔지니어링에 맞춰 조정되었습니다. 인터리브된 사고, 다단계 도구 호출, MCP 지원, 그리고 턴을 넘어 유지되는 추론이 특징입니다.
- 사고 토큰이 K2.6보다 약 30% 적으면서 코딩 점수는 더 높은데, 이는 출력 토큰당 과금될 때 중요합니다.
- 총 파라미터 1T, 활성 32B, 384개의 전문가, INT4 네이티브 지원, 그리고 이미지 입력을 위한 400M 파라미터 비전 인코더를 갖추고 있습니다.
- 오픈 웨이트, Modified MIT. 전체를 내려받아 vLLM이나 SGLang으로 직접 서빙할 수 있습니다.
그리고 솔직한 부분입니다. Moonshot은 프런티어와의 비교를 직접 공개했고, 거기서 K2.7 Code는 뒤집니다.
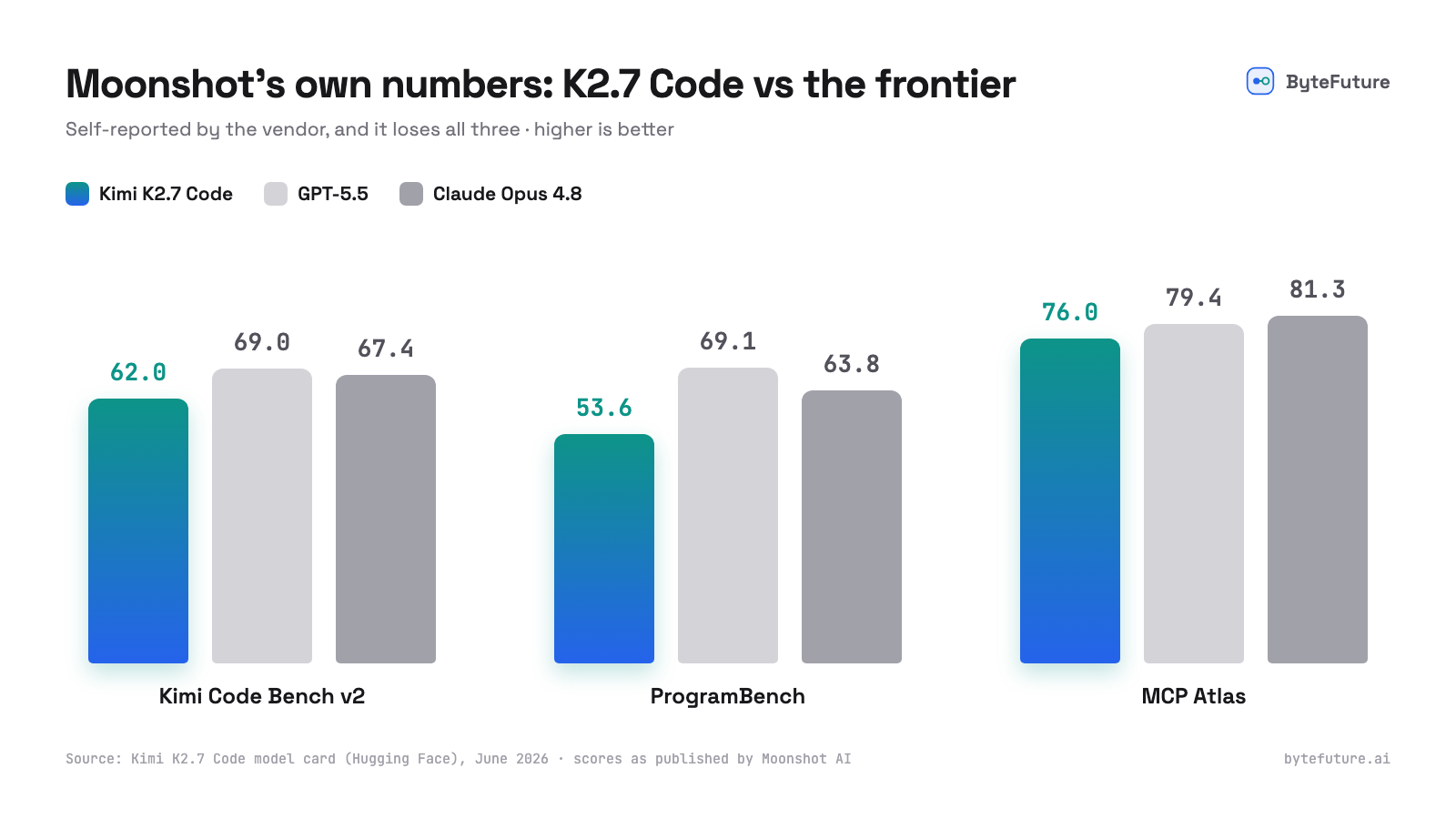
자사 모델이 지는 벤치마크를 공개하는 벤더는 그 수치가 정직하다는 좋은 신호이며, 격차도 민망한 수준은 아닙니다. Moonshot의 코딩 벤치에서 GPT-5.5에 약 7점 뒤지고, 도구 사용에서는 더 가깝습니다. 직전의 Kimi(K2.6)는 현재 Artificial Analysis Intelligence Index에서 가장 뛰어난 오픈 웨이트 모델입니다. 아직 아무도 모르는 것은 K2.7 Code가 여러분의 코드베이스에서, 여러분의 환경에서, 긴 에이전트 세션 동안 어떻게 행동하느냐입니다. 이 실험이 풀어낼 미지수가 바로 그것입니다.
저희 Grok Build 글과 같은 취지로 한 가지 분명히 해 둡니다. 모델로서의 K2.7 Code는 Moonshot 자체 코딩 환경인 Kimi Code CLI에 맞춰 최적화되어 있습니다. 그 CLI가 필요하지는 않습니다. 이 모델은 OpenAI 호환 및 Anthropic 호환 API를 구사하며, Token Station이 기존 환경이 보내는 무엇이든 변환해 줍니다.
가격: 프런티어 옆에서는 반올림 오차 수준
아래 모델들은 모두 각 제공사의 정가 그대로 Token Station에서 이용할 수 있습니다.
| 모델 | 입력 / 1M | 출력 / 1M | 컨텍스트 |
|---|---|---|---|
kimi/kimi-k2.7-code | $0.95 | $4.00 | 256K |
xai/grok-build-0.1 | $1.00 | $2.00 | 256K |
anthropic/claude-sonnet-4-6 | $3.00 | $15.00 | 1M |
anthropic/claude-opus-4-8 | $5.00 | $25.00 | 1M |
openai/gpt-5.5 | $5.00 | $30.00 | 1M |
anthropic/claude-fable-5 | $10.00 | $50.00 | 1M |
K2.7 Code 가격으로 치면 1달러의 가입 크레딧으로 약 100만 개의 입력 토큰 또는 25만 개의 출력 토큰을 살 수 있습니다. 같은 크레딧으로 Fable 5라면 프롬프트 몇 번 분량이었지만, 여기서는 제대로 된 평가를 할 수 있습니다. 이 실험의 하방 위험은 반올림하면 0입니다. 게다가 첫 충전 시 최대 50달러의 보너스 크레딧이 더해지며, K2.7 Code 가격이면 몇 주치 분량입니다.
진짜 실험: 일을 나누기
코딩 에이전트는 이미 작업을 계층으로 나눕니다. 계획과 어려운 추론이 일어나는 메인 루프가 있고, 팬아웃이 있습니다. 파일을 읽고, 검색을 돌리고, 테스트를 실행하고, 결과를 요약하는 서브에이전트들이죠. 팬아웃은 토큰의 대부분을 소모하지만 필요한 영민함은 가장 적습니다.
바로 그 분담에서 100만당 4달러짜리 모델이 100만당 50달러짜리 모델 옆에 자리를 얻습니다. Fable 5나 Opus 4.8을 운전석에 두고, 일상적인 작업은 K2.7 Code에 넘기세요. Moonshot의 수치가 실제로도 유지된다면, 위임된 작업의 품질 저하는 작고, 위임된 토큰마다 비용 절감은 10배가 넘습니다.
필요한 것
- Token Station 계정(무료 가입. 1달러 크레딧, 카드 불필요, Moonshot 계정도 불필요)
- 여러분의 Token Station API 키(
gw-로 시작) - 설치된 Claude Code, Codex 또는 OpenClaw
Claude Code 설정: 2단계 분담
Claude Code는 모델 계층을 환경 변수로 노출하므로, 일을 나누는 실험을 돌리기에 가장 깔끔한 곳입니다. Opus 자리는 Claude Fable 5를 위해 남겨 두고, 나머지는 전부 주력 모델에 맡기세요.
# Token Station endpoint + auth
export ANTHROPIC_BASE_URL="https://models.bytefuture.ai"
export ANTHROPIC_AUTH_TOKEN="gw-YOUR_TOKEN_STATION_KEY"
# Top tier: Fable 5 takes the genuinely hard problems
export ANTHROPIC_DEFAULT_OPUS_MODEL="anthropic/claude-fable-5"
# Everything else runs on the workhorse
export ANTHROPIC_DEFAULT_SONNET_MODEL="kimi/kimi-k2.7-code"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="kimi/kimi-k2.7-code"
export CLAUDE_CODE_SUBAGENT_MODEL="kimi/kimi-k2.7-code"
claude이제 평범한 세션이 처음부터 끝까지 K2.7 Code로 돌아갑니다. 메인 루프, 모든 서브에이전트, 모든 백그라운드 검색이 출력 100만당 50달러가 아니라 4달러로 과금됩니다. 어떤 문제가 정말로 프런티어급 판단을 요구할 때는 /model opus로 승격하면 Fable 5가 넘겨받고, 어려운 부분이 끝나면 다시 내려옵니다. 비싼 모델은 그 가격에 걸맞은 역할, 즉 필요할 때 불러오는 전문가가 됩니다.
Fable 5의 가격이 부담스럽다면 Opus 자리의 anthropic/claude-fable-5를 anthropic/claude-opus-4-8로 바꾸세요. 이 승격 패턴은 어떤 계층에서도 작동합니다.
Codex 설정
Codex는 세션당 모델 하나만 돌리지만, profiles를 쓰면 호출 단위로 동일한 분담을 할 수 있습니다. 주력 모델을 기본값으로 두고, Fable 5를 위한 이름 붙은 승격 프로필을 따로 마련해 두세요.
mkdir -p ~/.codex
cat > ~/.codex/config.toml <<'EOF'
# Default: the workhorse
model = "kimi/kimi-k2.7-code"
model_provider = "token_station"
[model_providers.token_station]
name = "token_station"
base_url = "https://models.bytefuture.ai/v1"
env_key = "TOKEN_STATION_API_KEY"
wire_api = "responses"
# Escalation: Fable 5 on demand
[profiles.deep]
model = "anthropic/claude-fable-5"
EOF
export TOKEN_STATION_API_KEY="gw-YOUR_TOKEN_STATION_KEY"
codex # routine work on K2.7 Code
codex --profile deep # hard problems on Fable 5평소에는 그냥 codex를 실행해 주력 모델 요금만 냅니다. 어떤 작업이 프런티어 모델을 쓸 만할 때만 codex --profile deep이 그 호출에 한해 Fable 5를 불러옵니다. 설정의 다른 부분은 전혀 움직이지 않습니다.
OpenClaw 설정
OpenClaw는 이 분담을 일급 설정으로 만듭니다. agents.defaults.subagents.model이 달리 지정하지 않는 한 서브에이전트는 호출자의 모델을 상속하므로(문서), Fable 5가 운전석에 앉은 채 생성되는 모든 서브에이전트를 K2.7 Code로 돌릴 수 있습니다.
{
"models": {
"mode": "merge",
"providers": {
"token-station": {
"baseUrl": "https://models.bytefuture.ai/v1",
"apiKey": "${TOKEN_STATION_API_KEY}",
"api": "anthropic-messages",
"models": [
{
"id": "anthropic/claude-fable-5",
"name": "Claude Fable 5 (Token Station)",
"contextWindow": 1000000,
"maxTokens": 128000
},
{
"id": "kimi/kimi-k2.7-code",
"name": "Kimi K2.7 Code (Token Station)",
"contextWindow": 256000,
"maxTokens": 32768
}
]
}
}
},
"agents": {
"defaults": {
"model": { "primary": "token-station/anthropic/claude-fable-5" },
"subagents": { "model": "token-station/kimi/kimi-k2.7-code" }
}
}
}메인 에이전트는 프런티어급 판단을 유지하고, 병렬 팬아웃(토큰을 소모하는 부분)은 주력 모델 요금으로 과금됩니다. 전체를 대신 K2.7 Code로 돌리려면 agents.defaults.model.primary를 그쪽으로 가리키게 하면 됩니다. 어느 쪽이든 두 모델은 같은 키 뒤에 있습니다.
알아 두면 좋은 특징들
- 사고는 항상 켜져 있다. K2.7 Code는 답하기 전에 추론하고 그 추론을 턴을 넘어 이어 갑니다. 이를 끌 수는 없습니다. 출력 청구서에 추론 토큰을 감안해 두세요. K2.6 대비 30% 줄어든 덕분에 부담은 덜합니다.
- 256K 컨텍스트. 넉넉하지만, 프런티어 Claude 및 GPT 모델의 1M 윈도의 4분의 1입니다. 긴 에이전트 세션은 더 일찍 압축됩니다.
- 홈팀 환경이 있다. Moonshot은 Kimi Code CLI에 맞춰 조정하므로, 다른 곳에서는 가끔 거친 부분이 나타날 수 있습니다. Token Station의 도구 및 파라미터 이름 변환이 프로토콜 수준의 불일치를 처리합니다.
- 나가는 길은 양방향이다. 실험이 실패하면 설정을 삭제하면 됩니다. 성공하면, 가중치는 Hugging Face에 Modified MIT로 공개되어 있어, 결국 똑같은 모델을 자체 하드웨어에서 서빙할 수 있습니다. 자체 호스팅으로 졸업할 수 있는 클라우드 실험은 하이브리드 추론 이야기를 축소해 놓은 것입니다.
실험을 돌려 보기
여러분의 비싼 모델에게는 과한 작업을 K2.7 Code에 맡기세요. 서브에이전트 검색, 테스트 실행, 보일러플레이트, 요약 같은 것들입니다. 한 주 동안 어디서 버티고 어디서 헛발질하는지 지켜본 뒤, 그에 맞춰 분담을 정하세요. 같은 Token Station 키로 anthropic/claude-fable-5, anthropic/claude-opus-4-8, kimi/kimi-k2.7-code를 나란히 돌릴 수 있으니, 비교는 처음부터 내장되어 있습니다.
models.bytefuture.ai에서 가입하고(1달러 무료 크레딧, 카드 불필요, 첫 충전 시 최대 50달러 보너스), 공개된 지 하루밖에 안 된 오픈 웨이트 모델이 10분의 1 가격으로 여러분 에이전트 작업량의 절반을 감당할 수 있는지 직접 확인해 보세요.