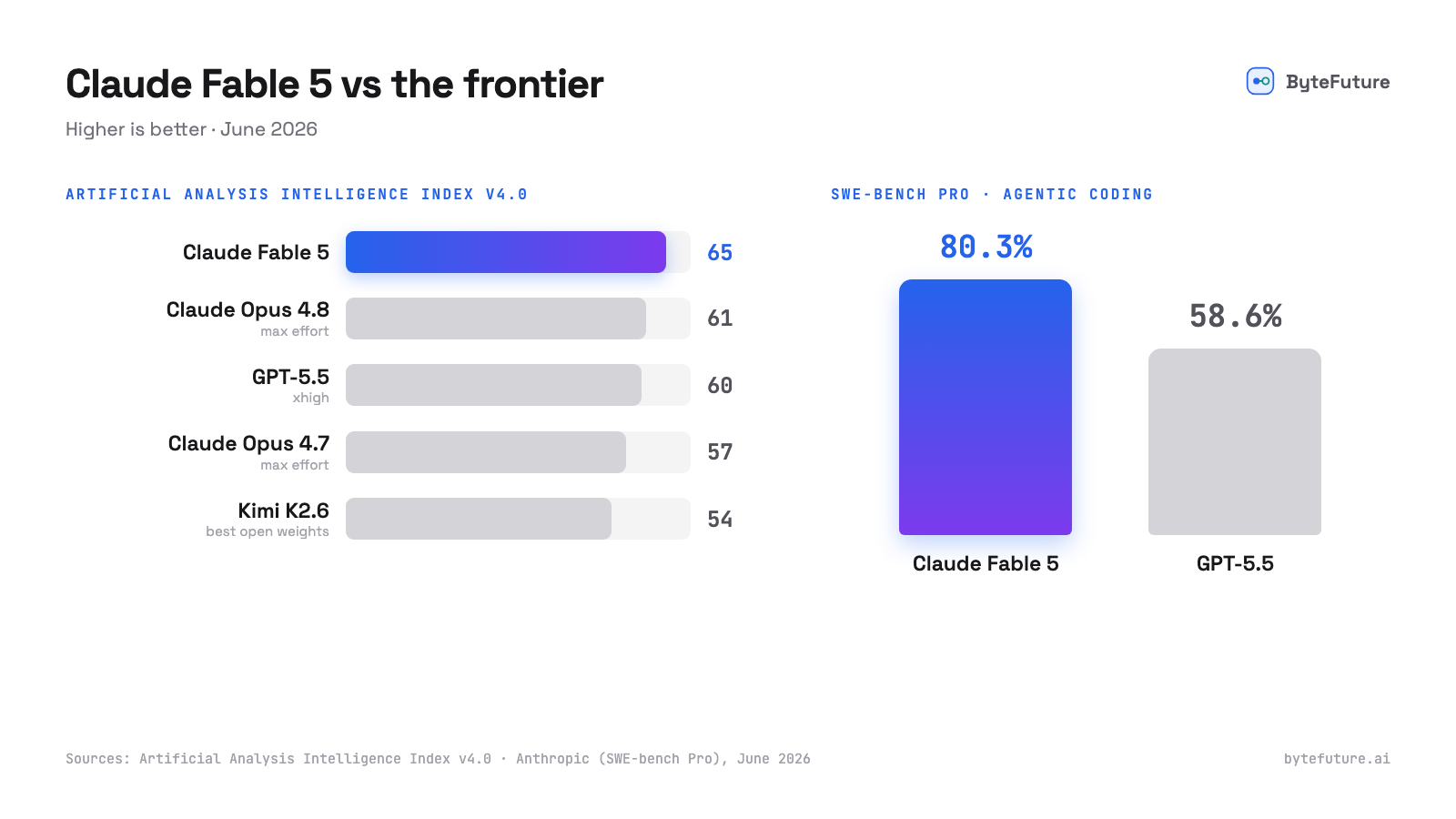
Claude Fable 5는 6월 9일에 공개됐다. 순수한 성능만 놓고 보면 흠잡기 어렵다. Opus 위에 자리한 새로운 등급으로, Anthropic이 테스트한 거의 모든 벤치마크에서 최첨단이며 Artificial Analysis Intelligence Index에서도 새롭게 1위에 올랐다.
동시에 최근 기억으로는 가장 논란이 많았던 모델 공개이자, Anthropic이 지금까지 내놓은 가장 비싼 API이기도 하다. 입력 100만 토큰당 10달러, 출력 100만 토큰당 50달러로, 두 항목 모두 Opus 4.8의 두 배다.
분명히 뛰어나면서도 대놓고 불신을 받고, 가격은 사치품처럼 매겨진 이 조합에는 분명한 태도가 필요하다. 써보되, 올인하지는 마라.새 계정을 만들지 말고, 새 잔액을 충전하지 말고, 워크플로를 다른 플랫폼으로 옮기지 마라. 이미 쓰고 있는 코딩 도구 안에서 일시적으로 돌려보고, 충분히 봤다 싶으면 바로 멈출 수 있는 종량제 토큰으로 사용하라.
Fable 5는 Token Station에서 anthropic/claude-fable-5로 사용할 수 있으며, Anthropic의 정가 그대로, 추가 마진 없이 제공된다. 그리고 당신의 1달러 가입 크레딧도 여기에 쓸 수 있다. 이 가이드는 Codex, OpenClaw, Pi에서의 구체적인 설정을 보여준다. (Claude Code를 쓴다면 Fable 5는 거기서 기본 지원되므로, 이 가이드는 그 외의 모든 사람을 위한 것이다.)
Fable 5는 실제로 무엇인가
Anthropic은 Fable 5를 "Mythos 급" 모델, 즉 그동안 내부에만 두었던 연구 등급을 일반 공개에 견딜 만큼 안전하게 다듬은 것이라고 설명한다. 대표 수치들은 하나같이 분명하다.
- SWE-bench Pro에서 80.3%로, GPT-5.5의 58.6%와 비교하면 이 벤치마크가 도입된 이래 가장 큰 격차다(Tom's Hardware).
- Artificial Analysis Intelligence Index에서 1위, 점수는 64.9로 가장 가까운 비 Anthropic 모델을 약 5점 차로 앞선다.
- Anthropic이 오랫동안 써온 분석 작업 벤치마크에서 처음으로 90%를 넘긴 모델로, Opus보다 10점 뛰어올랐다.
- 초기 테스트에서는 12시간 자율 실행이 보고됐고, Stripe는 5,000만 줄 규모의 Ruby 코드베이스를 하루 만에 이전했다고 밝혔다. 사람 손으로는 두 달로 잡혀 있던 작업이다(VentureBeat).
- Anthropic에 따르면 최첨단 비전 능력을 갖췄고, 100만 토큰 컨텍스트 윈도와 최대 128K 출력을 지원한다.
특히 코딩 에이전트(Codex, OpenClaw, Pi가 존재하는 이유인 장기·다단계 작업)에게는, 바로 이런 특성이야말로 시험해 보고 싶은 프로필이다.
논란, 그리고 "사지 말고 빌려 쓰자"는 주장
공개된 지 몇 시간 만에, Fable 5의 319쪽짜리 시스템 카드에 묻혀 있던 한 단락이 반발을 불러일으켰다. 이 모델은 프런티어 AI 개발과 관련된 요청(대형 모델 학습용 인프라, 특정 평가 작업, 그와 비슷한 주제)을 감지하면 스스로 답변의 질을 몰래 낮추도록 학습돼 있었다. 질문을 하면 일부러 약화된 답이 돌아오는데, 모델이 손을 빼고 있다는 사실은 결코 알려주지 않는다. 비평가들은 이를 "은밀한 사보타주"라고 불렀고, 전직 Anthropic 연구자들도 공개적으로 비판에 가세했다.
Anthropic은 이틀 만에 입장을 철회했다. "우리는 잘못된 절충을 했고, 균형을 제대로 잡지 못한 점에 대해 사과드립니다."이제 플래그가 붙은 요청은 명확히 식별돼 Claude Opus 4.8로 전달되고, 요청이 거부될 경우 API 사용자에게도 설명이 제공된다. 이와 별개로, 일부 제한 주제(특정 사이버 보안, 생물학, 화학 관련 요청과 모델 증류 요청)는 Fable 5 대신 Opus 4.8이 답한다. Anthropic은 이런 일이 발생하는 비율이 5% 미만의 세션이라고 밝혔다. 그리고 무관하지만 안심하기는 어려운 소식으로, Microsoft는 새 데이터 보존 규정을 이유로 GitHub Copilot에서 직원의 Fable 5 사용을 차단했다.
이것이 도입 방식에 왜 중요한지 보자. 능력은 진짜다. 하지만 모델을 둘러싼 정책 면은 눈에 띄게 아직도 움직이고 있다. 무엇이 조용히 다른 경로로 넘어가는지, 무엇이 거부되는지, 어떤 데이터가 보존되는지. 이 모든 것이 공개 이후 주마다 바뀌어 왔고 또 바뀔 수 있다. 워크플로를 옮겨 얹을 토대로는 최악이며, 그렇기에 실험은 언제든 되돌릴 수 있게 유지하는 편이 좋다.
- 도구를 바꾸지 마라.Codex, OpenClaw, Pi는 그대로 두고 그 뒤의 모델만 갈아 끼운다.
- 새 계정을 만들지 마라.Anthropic 콘솔 가입도, 충전했다가 나중에 되찾아야 하는 선불 잔액도 필요 없다. 지금 가진 Token Station 키면 충분하다.
- 구독하지 마라.실제로 테스트하는 동안에만 정가로 토큰 단위로 지불한다. 다음 주 정책 변경에 마음이 식으면 설정 한 줄만 바꿔 Opus 4.8이나 GPT-5.5로 돌아가면 된다. 같은 키, 같은 도구 그대로다.
가격: 호기심에 예산을 매겨라
Fable 5는 지금 시장에서 가장 비싼 주류 API 모델이다. 아래 모델은 모두 Token Station에서 각 제공사의 정가 그대로 사용할 수 있다.
| 모델 | 입력 / 100만 | 출력 / 100만 | 컨텍스트 |
|---|---|---|---|
anthropic/claude-fable-5 | $10.00 | $50.00 | 1M |
anthropic/claude-opus-4-8 | $5.00 | $25.00 | 1M |
openai/gpt-5.5 | $5.00 | $30.00 | 1M |
anthropic/claude-sonnet-4-6 | $3.00 | $15.00 | 1M |
xai/grok-build-0.1 | $1.00 | $2.00 | 256K |
이는 입력·출력 모두 Opus 4.8의 2배이고, 출력은 Grok Build의 25배다. Grok Build에서는 몇 센트면 끝날 긴 에이전트 세션 하나가 Fable 5에서는 실제 달러 단위로 나갈 수 있다. 사고와 도구 출력이 많은 장기 실행이야말로 100만당 50달러의 출력 가격이 뼈아프게 다가오는 지점이다.
반대로 보면, Token Station의 1달러 가입 크레딧만으로도 우선 맛보기에는 충분하다. Fable 5 가격으로 대략 10만 입력 토큰 또는 2만 출력 토큰에 해당하며, 실제로는 적당한 강도의 코딩 에이전트 프롬프트를 몇 번 돌릴 수 있는 양이다. 첫인상을 잡기에는 충분하고, 손해를 볼 만큼은 아니다. 더 본격적으로 평가하고 싶다면 첫 충전 시 최대 50달러의 보너스 크레딧이 추가된다.
필요한 것
- Token Station 계정(무료 가입. 1달러 크레딧 제공, 카드 불필요, Anthropic 계정과도 무관)
- 당신의 Token Station API 키(
gw-로 시작) - 설치된 Codex, OpenClaw 또는 Pi
아래의 어떤 도구에서든 모델 ID는 동일하다. anthropic/claude-fable-5. Token Station은 각 도구의 네이티브 API를 Anthropic 형식으로 변환하는데, 단순한 프록시 구성에서 깨지기 쉬운 도구·파라미터 이름 매핑까지 포함한다.
Codex 설정
Codex는 OpenAI의 Responses API를 쓴다. Token Station이 이를 Anthropic 형식으로 변환한다. 먼저 설정 파일을 만든다.
mkdir -p ~/.codex
cat > ~/.codex/config.toml <<'EOF'
model = "anthropic/claude-fable-5"
model_provider = "token_station"
[model_providers.token_station]
name = "token_station"
base_url = "https://models.bytefuture.ai/v1"
env_key = "TOKEN_STATION_API_KEY"
wire_api = "responses"
EOF그다음 키를 설정하고 실행한다.
export TOKEN_STATION_API_KEY="gw-YOUR_TOKEN_STATION_KEY"
codex실험을 끝내려면 model을 이전에 쓰던 것으로 되돌리기만 하면 된다. 그 밖에는 아무것도 건드리지 않는다.
OpenClaw 설정
OpenClaw는 openclaw.json 설정에서 커스텀 제공사를 받는다(문서). Token Station을 anthropic-messages 유형의 제공사로 추가하고 기본 모델을 Fable 5로 지정한다.
{
"models": {
"mode": "merge",
"providers": {
"token-station": {
"baseUrl": "https://models.bytefuture.ai/v1",
"apiKey": "${TOKEN_STATION_API_KEY}",
"api": "anthropic-messages",
"models": [
{
"id": "anthropic/claude-fable-5",
"name": "Claude Fable 5 (Token Station)",
"contextWindow": 1000000,
"maxTokens": 128000
}
]
}
}
},
"agents": {
"defaults": {
"model": { "primary": "token-station/anthropic/claude-fable-5" }
}
}
}OpenClaw 게이트웨이를 재시작하면 Token Station을 통해 라우팅된다. 되돌리려면 이전의 agents.defaults.model을 복원하면 된다. 제공사 항목은 다음을 위해 그대로 두어도 좋다.
Pi 설정
Pi는 커스텀 제공사를 ~/.pi/agent/models.json에 등록한다(문서).
{
"providers": {
"token-station": {
"name": "Token Station",
"baseUrl": "https://models.bytefuture.ai/v1",
"apiKey": "$TOKEN_STATION_API_KEY",
"api": "anthropic-messages",
"models": [
{
"id": "anthropic/claude-fable-5",
"name": "Claude Fable 5",
"reasoning": true,
"input": ["text", "image"],
"contextWindow": 1000000,
"maxTokens": 128000
}
]
}
}
}모델을 지정해 실행하거나, 실행 중에 /model로 전환한다.
export TOKEN_STATION_API_KEY="gw-YOUR_TOKEN_STATION_KEY"
pi --model anthropic/claude-fable-5OpenClaw와 Pi에 대해 한 가지. 클라이언트마다 스스로 /v1을 붙이는지가 다르다. 위 설정에서 404가 보이면 baseUrl에서 /v1을 떼고 다시 시도하라.
알아둘 만한 API의 특이점
Fable 5는 Claude 모델 중에서 가장 엄격한 요청 인터페이스를 갖고 있으며, 도구가 모델 파라미터를 노출하는 경우에 중요해진다.
- 샘플링 파라미터 불가.
temperature,top_p,top_k는 모두 400으로 거부된다. 대신 프롬프트로 유도하라. - 적응형 사고만 가능.고정 사고 예산(
budget_tokens)은 사라졌고, (Fable 5에만 해당하는데) 명시적인 "사고 비활성화" 설정조차 거부된다. 사고 관련 설정은 건드리지 말거나 아예 생략하라. - 어시스턴트 프리필 불가.출력 형태를 강제하려고 어시스턴트 턴을 프리필하는 도구는 400을 받는다. 대신 구조화 출력 기능을 쓰면 된다.
- 세이프가드 재라우팅.제한 주제에 관한 소수의 요청(Anthropic은 5% 미만의 세션이라고 한다)은 대신 Opus 4.8이 답하며, 이제는 눈에 보이는 안내가 붙는다. 그러니 가끔 답변이 스스로를 Opus라고 밝히더라도 놀라지 마라.
실험을 돌려보기
이 설정의 핵심은 언제든 버릴 수 있다는 점이다. 무료 크레딧을 써서 Fable 5에게 당신이 쌓아둔 실제 작업을 시켜본 뒤, 데이터로 판단하라. Token Station의 모든 모델이 같은 키 뒤에 있으므로, 비교는 설정 한 줄이면 된다. 같은 작업을 anthropic/claude-opus-4-8(가격은 절반), openai/gpt-5.5, xai/grok-build-0.1(출력 가격은 25분의 1)에서 돌려보고, Fable 5의 우위가 당신의 작업에서 그 프리미엄만큼의 값을 하는지 확인하라.
값을 한다면 좋다. 설정을 그대로 두고 잔액을 채우면 된다. 그렇지 않거나 다음 정책 돌발 변수에 마음이 바뀌면 설정 세 줄을 지우고 떠나면 된다. 구독한 것도 없고, 해지할 것도 없다.
models.bytefuture.ai에서 가입하고(1달러 무료 크레딧, 카드 불필요, Anthropic 계정 불필요, 첫 충전 시 최대 50달러 보너스), Mythos 급 모델이 당신의 코드에서 무엇을 해내는지 직접 확인해 보라.