Open models are getting harder to dismiss.
For years, the assumption was simple: if you wanted the strongest model, you used a closed frontier model. Open models were useful, but mostly for experiments, cost savings, or self-hosting.
That assumption is starting to break.
We tested NVIDIA Nemotron-3 Ultra 550B-A55B, an American open model from NVIDIA, against GPT-5.5 on three real coding-agent tasks using Token Station Arena.
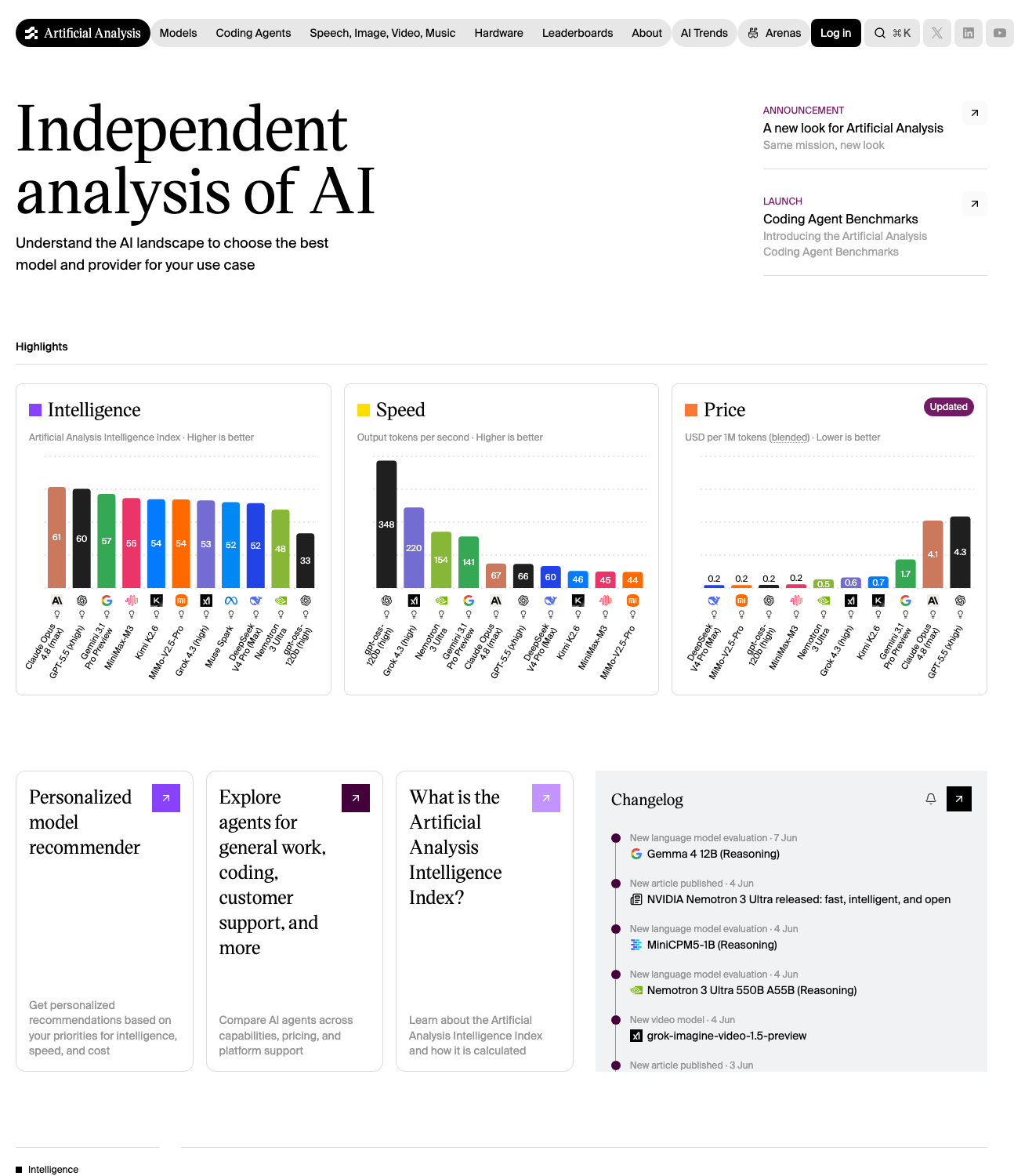
That standing is not just our read. On the Artificial Analysis Intelligence Index, Nemotron-3 Ultra scores 47.7, the highest of any American open-weights model and well ahead of the next US open models such as Gemma 4. It still sits behind the closed frontier and the strongest Chinese open models, but among American open weights nothing else is close.
The result was the story:
Nemotron-3 Ultra completed the same mini benchmark workload as GPT-5.5.
Both models passed 9 out of 9 runs.
This does not mean every open model beats every closed model. It means something more important for developers and companies:
American open models are now strong enough to compete on real agent workloads, not just toy prompts.
A note on access before we dig in: NVIDIA NIM is offering Nemotron-3 Ultra inference for free for a limited time, so Token Station offers it for free as well. And the free credits you get when you sign up for Token Station can go toward GPT-5.5 and Claude Fable 5, so you can evaluate all three on your own coding tasks.
Why this matters
The open-vs-closed model debate used to be mostly philosophical.
Open models gave developers more control. Closed models usually gave better performance.
And to be clear about the baseline: the closed frontier is still well ahead. Plot overall capability by release date, and the picture is stark:
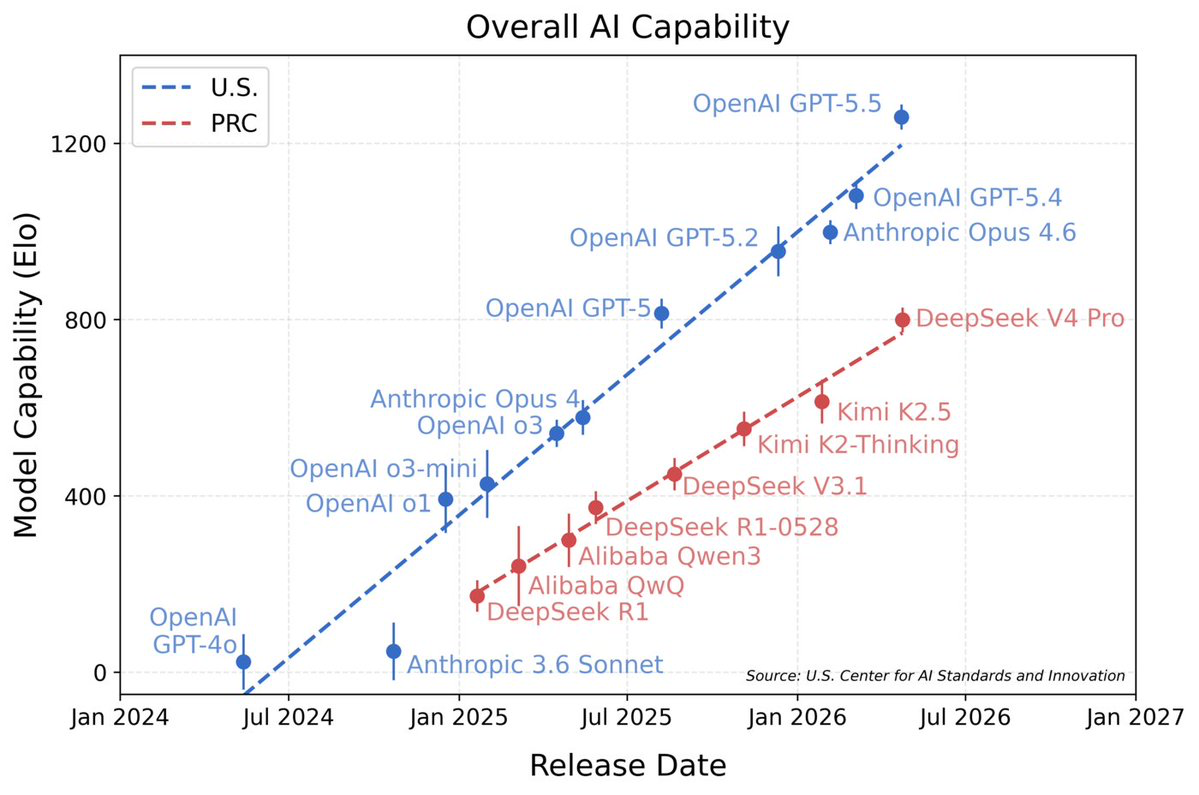
Two things stand out in that chart.
First, open models as a group still lag the closed frontier. Every model on the leading U.S. line (GPT-5.5, GPT-5.4, Anthropic's Opus series, and now Claude Fable 5, the current closed-frontier SOTA) is closed. The open-weight models that chart at all (DeepSeek, Qwen, Kimi) sit on a visibly lower trend line, hundreds of Elo points behind.
Second, and more striking: every open model on the chart is Chinese. American open models are nowhere to be found.
Against that backdrop, an American open model completing the same coding-agent mini benchmark tasks as GPT-5.5 changes the conversation.
The question is no longer:
Are open models useful?
The better question is:
Which workloads still require a closed frontier model, and which workloads can now run on a powerful open model?
That distinction matters for real products.
AI agents are not just chatbots. They read files, modify code, call tools, run tests, retry failed steps, and operate across long workflows. For this kind of usage, model choice is not only about raw capability. It is also about control, cost structure, availability, and whether the model can be adapted to the business.
That is where open models are becoming strategically important.
The American open model we tested
The open model in this mini benchmark was NVIDIA Nemotron-3 Ultra 550B-A55B.
Its model profile:
- 550B total parameters
- 55B active parameters
- MoE / latent-MoE style architecture
- Developed by NVIDIA, an American AI infrastructure company
- Inference free for a limited time via NVIDIA NIM, and served free on Token Station too
This is not a small model being used only because it is inexpensive. It is a large American open model designed for serious reasoning and agent workloads.
GPT-5.5 remains a leading closed frontier model. It is powerful, polished, and widely useful. The same goes for Claude Fable 5, Anthropic's newest flagship and a representative of the current closed-frontier SOTA. We don't yet have head-to-head numbers for it in this mini benchmark, but it is part of the bar that open models are chasing. Nemotron-3 Ultra represents a different kind of value: a strong open model with more transparent model characteristics and a more controllable deployment profile.
For developers and businesses, that matters.
The mini benchmark setup
We used Token Station Arena to run a coding-agent mini benchmark: a small, focused test, not a leaderboard. The runner, the three tasks, and every check are open source, so you can read exactly what was tested and reproduce it yourself.
The setup:
- 2 models: GPT-5.5 and NVIDIA Nemotron-3 Ultra 550B-A55B
- 3 coding-agent tasks
- 3 runs per task per model
- 18 total runs
The mini benchmark used deterministic checks such as unit tests, typecheck, clippy, and task-specific validation.
This is important because coding agents should not be judged only by whether their answers sound good. They need to make real code changes and pass checks.
The three coding-agent tasks
All three tasks live in the benchmark/tasks folder of the Arena repository. Each task is a self-contained Rust fixture project plus a prompt and a set of machine-checkable success criteria. Every task requires cargo test, cargo check, and cargo clippy --all-targets -- -D warnings to pass, and the judge fails any run that edits files outside the task's allowed paths, so an agent cannot pass by making unrelated changes or weakening the tests.
1. Add an API endpoint
This task tests whether the model can make a normal product development change inside an existing codebase: a small Rust workspace with a catalog-core library crate and a catalog-api Axum crate. The prompt, verbatim from the repo:
- Add `GET /products/top?limit=<n>` to the Axum app.
- Return JSON products sorted by descending popularity.
- Respect the optional `limit` query parameter. If it is
missing, return all products.
- Reuse existing catalog-core logic where possible.
- Do not remove or weaken the integration test.The agent has to understand the project structure, find the right route or handler, add the endpoint, return the expected response, and keep the project checks passing. This is the kind of task developers do every day. It is not a puzzle. It is practical engineering work.
2. Fix a failing test
This task tests debugging ability. The fixture ships with a broken pricing implementation in catalog-core and a failing unit test:
- Fix the failing pricing unit test in `catalog-core`.
- Preserve the public function names and signatures.
- Keep the implementation simple and idiomatic.
- Do not weaken, remove, or rewrite tests to hide the bug.The agent has to identify the underlying issue, fix the implementation, and restore passing tests without touching the test itself. This matters because real coding agents need to recover from failures. They cannot only write new code when everything is clean and obvious.
3. Refactor pricing logic
This task tests whether the model can improve code structure without changing business behavior:
- Refactor the duplicated discount calculation in
`catalog-core/src/pricing.rs`.
- Introduce one shared helper for computing the discount amount.
- Preserve all public function names, signatures, and behavior.
- Do not remove or weaken tests or the custom refactor check.On top of the standard checks, this task adds a fourth gate: a custom check-refactor.mjs script that verifies the duplication is actually gone. The agent has to preserve pricing rules while passing unit tests, typecheck, clippy, and that refactor-specific validation. This is closer to real production engineering than a simple code-generation prompt. The model has to understand both code and business logic.
Results
| Metric | GPT-5.5 | NVIDIA Nemotron-3 Ultra 550B-A55B |
|---|---|---|
| Completed runs | 9/9 | 9/9 |
| Average judge score | 5.0 | 4.8 |
The important result is task completion.
Both models completed every run.
That is the marketing signal:
An American open model completed the same coding-agent workload as GPT-5.5.
For developers, this is a meaningful shift. Open models are no longer just fallback options. They are becoming serious candidates for real agent systems.
Open models are catching up
The broader AI market is moving toward a multi-model world.
Closed models still matter. They often set the frontier and remain excellent choices for many high-value tasks.
But open models are catching up quickly. They are becoming capable enough for practical coding, reasoning, and agent workflows. They also offer advantages that closed models cannot always provide:
- More control over deployment strategy
- Better fit for private or internal workflows
- More predictable long-term infrastructure planning
- More flexibility for customization
- Less dependence on a single closed provider
Nemotron-3 Ultra is especially important because it is an American open model from NVIDIA. For companies that care about both AI capability and infrastructure control, that combination is strategically relevant.
What this means for Token Station
The future is not one model for every task.
Some workloads need a closed frontier model. Some workloads can now run on a powerful open model. Many teams will want to test both before deciding what to use in production.
That is exactly why Token Station (models.bytefuture.ai) exists.
With Token Station, developers can access models like Nemotron-3 Ultra, GPT-5.5, and other frontier models through one platform. Instead of choosing based on brand names or assumptions, teams can compare models on their own workloads.
The point is not to declare one universal winner.
The point is to make model choice practical.
Run it yourself
American open models are catching up with closed frontier models.
Nemotron-3 Ultra matching GPT-5.5 on our coding-agent mini benchmark is one more signal that the model landscape is changing.
And you don't have to take our word for it. The entire mini benchmark runs against any Anthropic-compatible gateway, so with a Token Station key and the claude CLI on your PATH, reproducing our runs is four commands:
git clone https://github.com/hydai/token-station-arena
cd token-station-arena
point the runner at Token Station (gateway root, no /v1)
export ANTHROPIC_BASE_URL=https://models.bytefuture.ai
export ANTHROPIC_AUTH_TOKEN=<your Token Station API key>
run all three tasks against the configured models
cargo run –release – benchmark –tasks all –models all –runs 3
The runner executes each task in an isolated fixture, applies the deterministic checks, and generates a Markdown report with tokens, cost, and timing per run. You can also drop your own tasks into benchmark/tasks/ (a fixture, a prompt.md, and a task.yml) and find out how these models do on your code, not ours.
Try Nemotron-3 Ultra (free for a limited time, courtesy of NVIDIA NIM) alongside GPT-5.5, Claude Fable 5, and other frontier models on Token Station.