开源模型越来越难以被轻视了。
多年来,假设很简单:想要最强的模型,就用闭源前沿模型。开源模型有用,但主要用于实验、节省成本或自托管。
这个假设正在开始动摇。
我们使用 Token Station Arena,在三个真实的编程智能体任务上,将 NVIDIA 推出的美国开源模型 NVIDIA Nemotron-3 Ultra 550B-A55B 与 GPT-5.5 进行了对比测试。
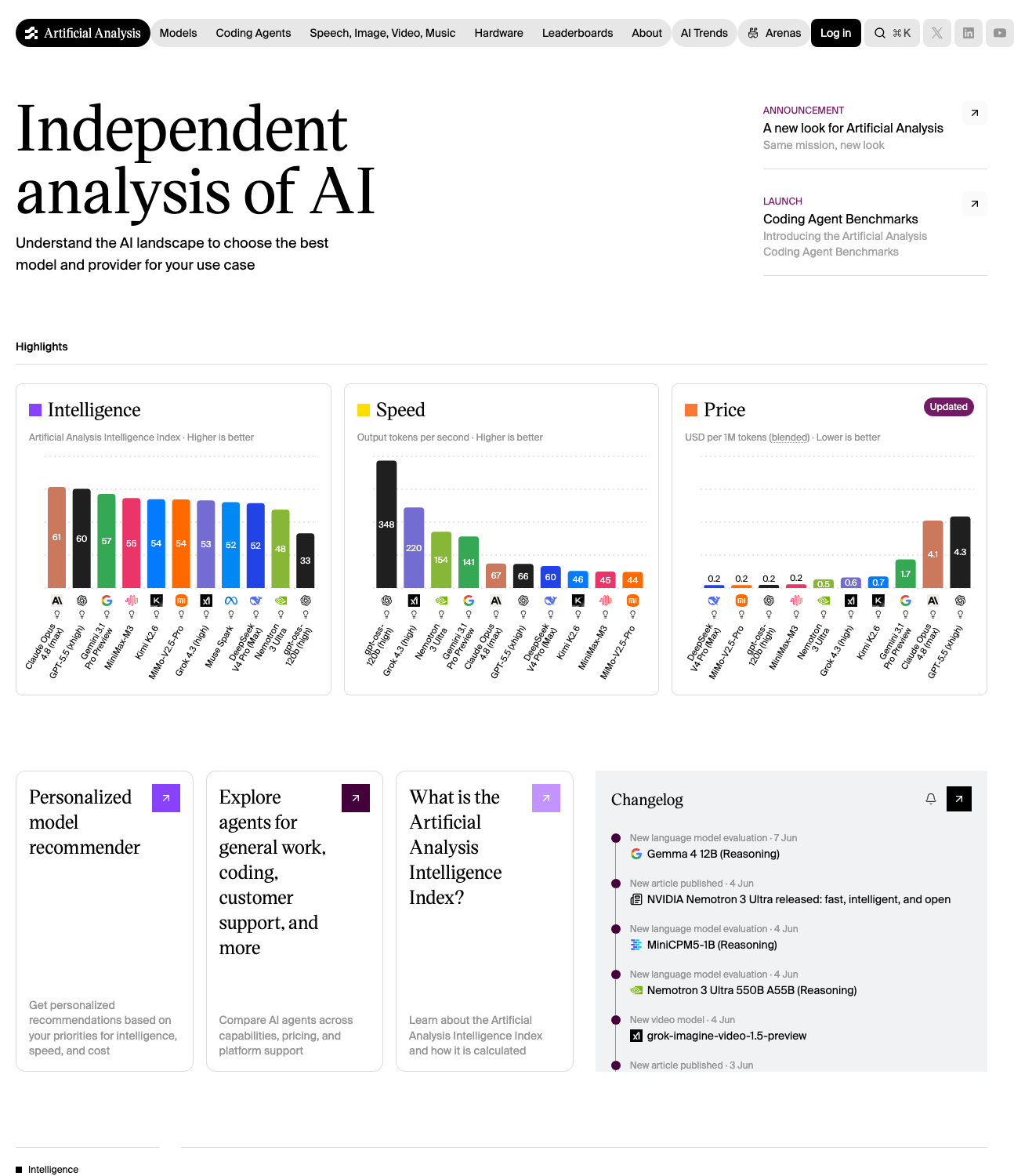
这一地位不只是我们的看法。在 Artificial Analysis Intelligence Index 上,Nemotron-3 Ultra 得分为 47.7,是所有美国开源权重模型中的最高分,远远领先于 Gemma 4 等紧随其后的美国开源模型。它仍落后于闭源前沿模型和最强的中国开源模型,但在美国开源权重模型中,没有任何对手能与它接近。
结果本身就是关键:
Nemotron-3 Ultra 完成了与 GPT-5.5 相同的迷你基准测试工作负载。
两款模型都在 9 次运行中通过了全部 9 次。
这并不意味着每一款开源模型都能胜过每一款闭源模型。它意味着对开发者和企业来说更重要的事:
美国开源模型如今已经足够强大,可以在真实的智能体工作负载上竞争,而不只是在玩具级提示上。
在深入之前,先说一句关于使用的事:NVIDIA NIM 正在限时免费提供 Nemotron-3 Ultra 推理,因此 Token Station 也免费提供它。而你注册 Token Station 时获得的免费额度可以用于 GPT-5.5 和 Claude Fable 5,因此你可以在自己的编程任务上同时评估这三款模型。
这为何重要
过去,开源与闭源模型之争大多停留在理念层面。
开源模型给开发者更多控制权。闭源模型通常提供更好的性能。
把基准说清楚:闭源前沿仍然遥遥领先。按发布日期绘制整体能力,画面一目了然:
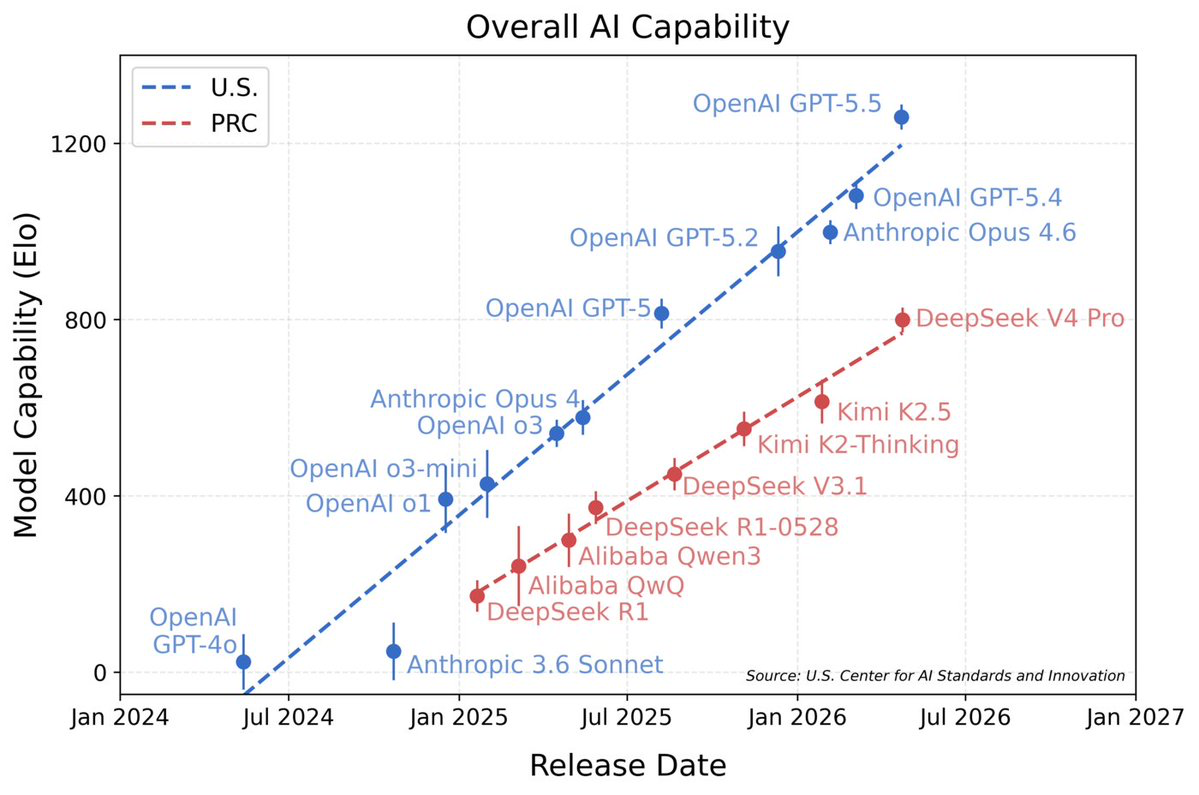
这张图里有两点格外醒目。
第一,开源模型作为一个整体仍落后于闭源前沿。处于美国领先曲线上的每一款模型(GPT-5.5、GPT-5.4、Anthropic 的 Opus 系列,以及如今代表当前闭源前沿 SOTA 的 Claude Fable 5)都是闭源的。能上榜的开源权重模型(DeepSeek、Qwen、Kimi)则明显处在更低的趋势线上,落后数百个 Elo 分。
第二,也更引人注目:图上每一款开源模型都来自中国。美国开源模型踪影全无。
在这样的背景下,一款美国开源模型完成与 GPT-5.5 相同的编程智能体迷你基准任务,改变了讨论的方向。
问题不再是:
开源模型有用吗?
更好的问题是:
哪些工作负载仍然需要闭源前沿模型,哪些工作负载现在已经可以跑在一款强大的开源模型上?
这个区分对真实产品至关重要。
AI 智能体不只是聊天机器人。它们读取文件、修改代码、调用工具、运行测试、重试失败的步骤,并在漫长的工作流中运转。对于这类用途,模型选择不仅关乎原始能力,还关乎控制权、成本结构、可用性,以及模型能否被适配到具体业务中。
正是在这里,开源模型变得具有战略意义。
我们测试的美国开源模型
本次迷你基准测试中的开源模型是 NVIDIA Nemotron-3 Ultra 550B-A55B。
它的模型概况:
- 5500 亿总参数
- 550 亿激活参数
- MoE / latent-MoE 风格架构
- 由美国 AI 基础设施公司 NVIDIA 开发
- 通过 NVIDIA NIM 限时免费推理,Token Station 上同样免费提供
这不是一款只因便宜而被使用的小模型。它是一款大型的美国开源模型,专为严肃的推理和智能体工作负载而设计。
GPT-5.5 仍是领先的闭源前沿模型。它强大、成熟、用途广泛。Anthropic 最新的旗舰、代表当前闭源前沿 SOTA 的 Claude Fable 5 也是如此。我们在这次迷你基准中还没有它的正面对比数据,但它正是开源模型所追赶的标杆的一部分。Nemotron-3 Ultra 代表着另一种价值:一款强大的开源模型,拥有更透明的模型特性和更可控的部署方式。
对开发者和企业而言,这很重要。
迷你基准测试的设置
我们使用 Token Station Arena 运行了一个编程智能体迷你基准测试:一个小而聚焦的测试,而非排行榜。运行器、这三个任务以及每一项检查都是开源的,因此你可以确切地了解测试内容,并自行复现。
设置如下:
- 2 款模型:GPT-5.5 和 NVIDIA Nemotron-3 Ultra 550B-A55B
- 3 个编程智能体任务
- 每个模型每个任务运行 3 次
- 共计 18 次运行
这次迷你基准使用了确定性检查,例如单元测试、类型检查、clippy 以及针对任务的专门验证。
这一点很重要,因为评判编程智能体不应只看它们的回答听起来是否漂亮。它们需要做出真实的代码改动并通过检查。
三个编程智能体任务
这三个任务都位于 Arena 仓库的 benchmark/tasks 目录中。每个任务都是一个自包含的 Rust 测试夹具项目,外加一段提示和一组可由机器检查的成功标准。每个任务都要求 cargo test、cargo check 以及 cargo clippy --all-targets -- -D warnings 全部通过,并且只要某次运行改动了任务允许路径之外的文件,评判就会判其失败,因此智能体无法靠做无关改动或削弱测试来蒙混过关。
1. 添加一个 API 端点
这个任务测试模型能否在现有代码库中完成一次常规的产品开发改动:一个小型 Rust 工作区,包含一个 catalog-core 库 crate 和一个 catalog-api Axum crate。提示如下,原文取自仓库:
- Add `GET /products/top?limit=<n>` to the Axum app.
- Return JSON products sorted by descending popularity.
- Respect the optional `limit` query parameter. If it is
missing, return all products.
- Reuse existing catalog-core logic where possible.
- Do not remove or weaken the integration test.智能体必须理解项目结构、找到正确的路由或处理器、添加端点、返回预期的响应,并让项目的各项检查继续通过。这正是开发者每天都在做的那类任务。它不是谜题,而是实打实的工程工作。
2. 修复一个失败的测试
这个任务测试调试能力。该测试夹具中带有一个 catalog-core 里出错的定价实现,以及一个失败的单元测试:
- Fix the failing pricing unit test in `catalog-core`.
- Preserve the public function names and signatures.
- Keep the implementation simple and idiomatic.
- Do not weaken, remove, or rewrite tests to hide the bug.智能体必须找出根本问题、修复实现,并在不改动测试本身的前提下让测试重新通过。这一点很重要,因为真实的编程智能体需要能从失败中恢复。它们不能只在一切干净明了时才写新代码。
3. 重构定价逻辑
这个任务测试模型能否在不改变业务行为的前提下改善代码结构:
- Refactor the duplicated discount calculation in
`catalog-core/src/pricing.rs`.
- Introduce one shared helper for computing the discount amount.
- Preserve all public function names, signatures, and behavior.
- Do not remove or weaken tests or the custom refactor check.在标准检查之上,这个任务还增加了第四道关卡:一个自定义的 check-refactor.mjs 脚本,用于验证重复确实被消除了。智能体必须在保留定价规则的同时,通过单元测试、类型检查、clippy 以及那项针对重构的专门验证。这比一个简单的代码生成提示更接近真实的生产工程。模型必须同时理解代码和业务逻辑。
结果
| 指标 | GPT-5.5 | NVIDIA Nemotron-3 Ultra 550B-A55B |
|---|---|---|
| 完成的运行 | 9/9 | 9/9 |
| 评判平均分 | 5.0 | 4.8 |
重要的结果是任务完成度。
两款模型都完成了每一次运行。
这就是值得对外传达的信号:
一款美国开源模型完成了与 GPT-5.5 相同的编程智能体工作负载。
对开发者来说,这是一次有意义的转变。开源模型不再只是退而求其次的选项,它们正在成为真实智能体系统的认真候选。
开源模型正在追赶
更广阔的 AI 市场正在走向一个多模型的世界。
闭源模型依然重要。它们常常定义前沿,并且对许多高价值任务而言仍是出色的选择。
但开源模型正在快速追赶。它们正变得足够强大,能够胜任实际的编程、推理和智能体工作流。它们还提供了闭源模型并不总能给予的优势:
- 对部署策略有更多控制权
- 更适合私有或内部工作流
- 长期基础设施规划更可预测
- 定制时更具灵活性
- 对单一闭源供应商的依赖更少
Nemotron-3 Ultra 尤为重要,因为它是一款来自 NVIDIA 的美国开源模型。对于既看重 AI 能力又看重基础设施控制权的企业来说,这一组合具有战略意义。
这对 Token Station 意味着什么
未来不是一款模型应对所有任务。
有些工作负载需要闭源前沿模型。有些工作负载现在已经可以跑在一款强大的开源模型上。许多团队会希望在决定生产环境用什么之前,先把两者都试一试。
这正是 Token Station(models.bytefuture.ai)存在的原因。
借助 Token Station,开发者可以通过一个平台访问 Nemotron-3 Ultra、GPT-5.5 等前沿模型。团队不必再依据品牌名或假设来选择,而是可以在自己的工作负载上对比模型。
重点不是要宣布一个放之四海皆准的赢家。
重点是让模型选择变得切实可行。
自己跑一遍
美国开源模型正在追赶闭源前沿模型。
Nemotron-3 Ultra 在我们的编程智能体迷你基准上与 GPT-5.5 打平,是模型格局正在变化的又一个信号。
而且你不必只听我们的说法。整个迷你基准可以在任何兼容 Anthropic 的网关上运行,因此只要有一把 Token Station 密钥,并把 claude CLI 放进你的 PATH,复现我们的运行只需四条命令:
git clone https://github.com/hydai/token-station-arena
cd token-station-arena
point the runner at Token Station (gateway root, no /v1)
export ANTHROPIC_BASE_URL=https://models.bytefuture.ai
export ANTHROPIC_AUTH_TOKEN=<your Token Station API key>
run all three tasks against the configured models
cargo run –release – benchmark –tasks all –models all –runs 3
运行器会在隔离的测试夹具中执行每个任务,应用确定性检查,并生成一份 Markdown 报告,记录每次运行的 token 数、成本和耗时。你也可以把自己的任务放进 benchmark/tasks/(一个测试夹具、一个 prompt.md 和一个 task.yml),看看这些模型在你的代码上、而不是我们的代码上表现如何。
在 Token Station 上试用 Nemotron-3 Ultra(由 NVIDIA NIM 提供,限时免费),并与 GPT-5.5、Claude Fable 5 等前沿模型一同对比。