オープンモデルを軽く見ることが、ますます難しくなっている。
長年、前提はシンプルだった。最強のモデルが欲しければ、クローズドな最前線のモデルを使う。オープンモデルは便利だが、主に実験やコスト削減、セルフホスティングのためのものだった。
その前提が崩れ始めている。
Token Station Arena を使い、NVIDIA が手がけるアメリカのオープンモデル NVIDIA Nemotron-3 Ultra 550B-A55B を、3 つの実際のコーディングエージェントのタスクで GPT-5.5 と比較検証した。
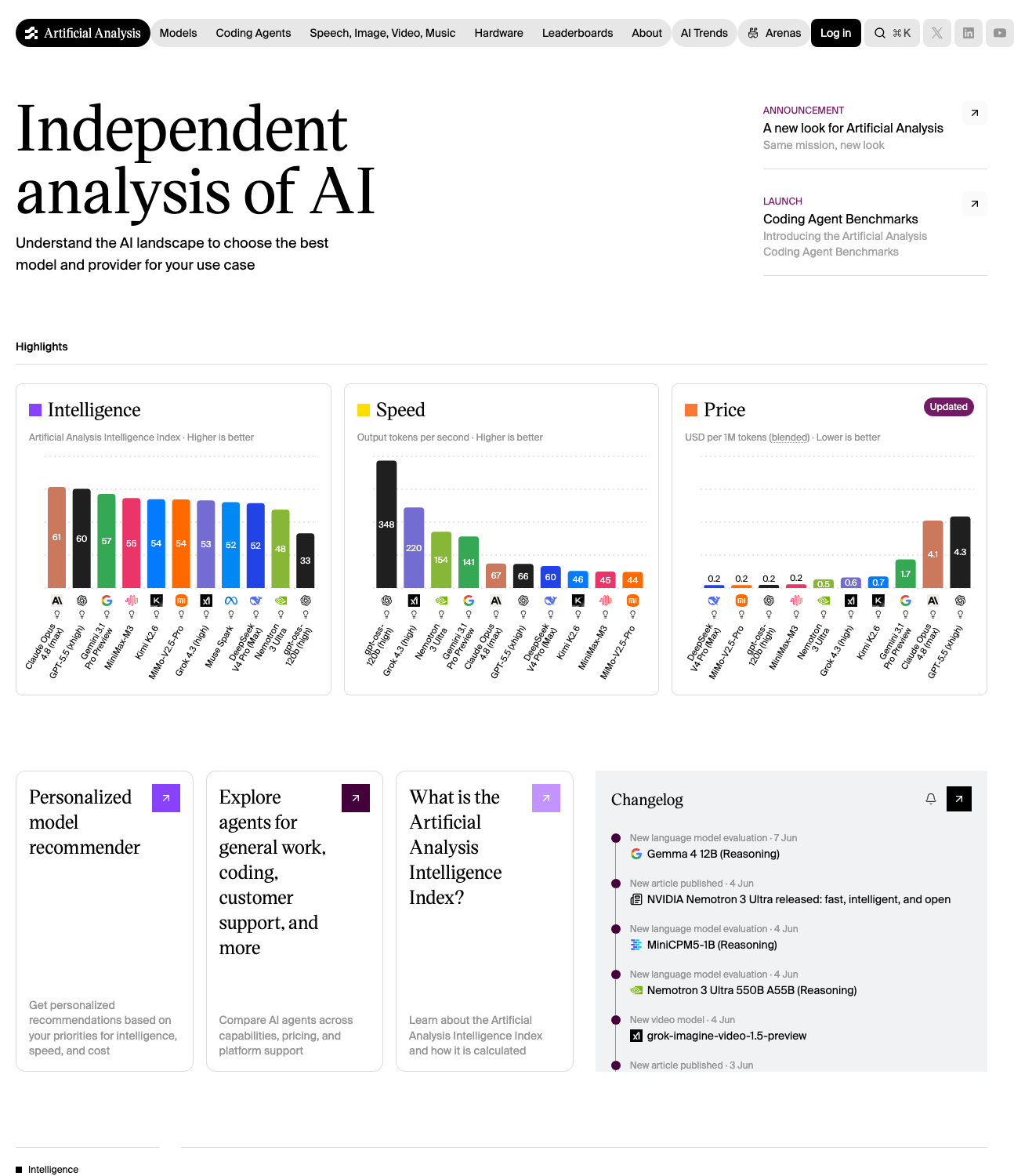
この位置づけは、私たちだけの見立てではない。Artificial Analysis Intelligence Index において Nemotron-3 Ultra は 47.7 を記録し、アメリカのオープンウェイトモデルの中で最高、Gemma 4 をはじめとする次点の米国オープンモデルを大きく引き離している。クローズドな最前線や最強の中国オープンモデルにはなお及ばないが、アメリカのオープンウェイトの中で肩を並べるものはない。
結果こそが核心だった。
Nemotron-3 Ultra は GPT-5.5 と同じミニベンチマークのワークロードを完遂した。
両モデルとも 9 回中 9 回 をパスした。
これは、あらゆるオープンモデルがあらゆるクローズドモデルに勝つという意味ではない。開発者や企業にとって、もっと重要なことを意味している。
アメリカのオープンモデルはいまや、おもちゃのようなプロンプトだけでなく、実際のエージェントのワークロードで競えるほど強くなっている。
本題に入る前に、利用についてひとこと。NVIDIA NIM は期間限定で Nemotron-3 Ultra の推論を無料提供している。そのため Token Station でも無料で利用できる。さらに Token Station に登録するともらえる無料クレジットは GPT-5.5 や Claude Fable 5 にも使えるので、3 つすべてを自分のコーディングタスクで評価できる。
なぜこれが重要なのか
オープン対クローズドのモデル論争は、かつてはおおむね理念的なものだった。
オープンモデルは開発者により多くの制御を与えた。クローズドモデルはたいてい高い性能を与えた。
前提をはっきりさせておく。クローズドな最前線はいまも大きく先行している。総合的な能力をリリース日で並べると、構図は鮮明だ。
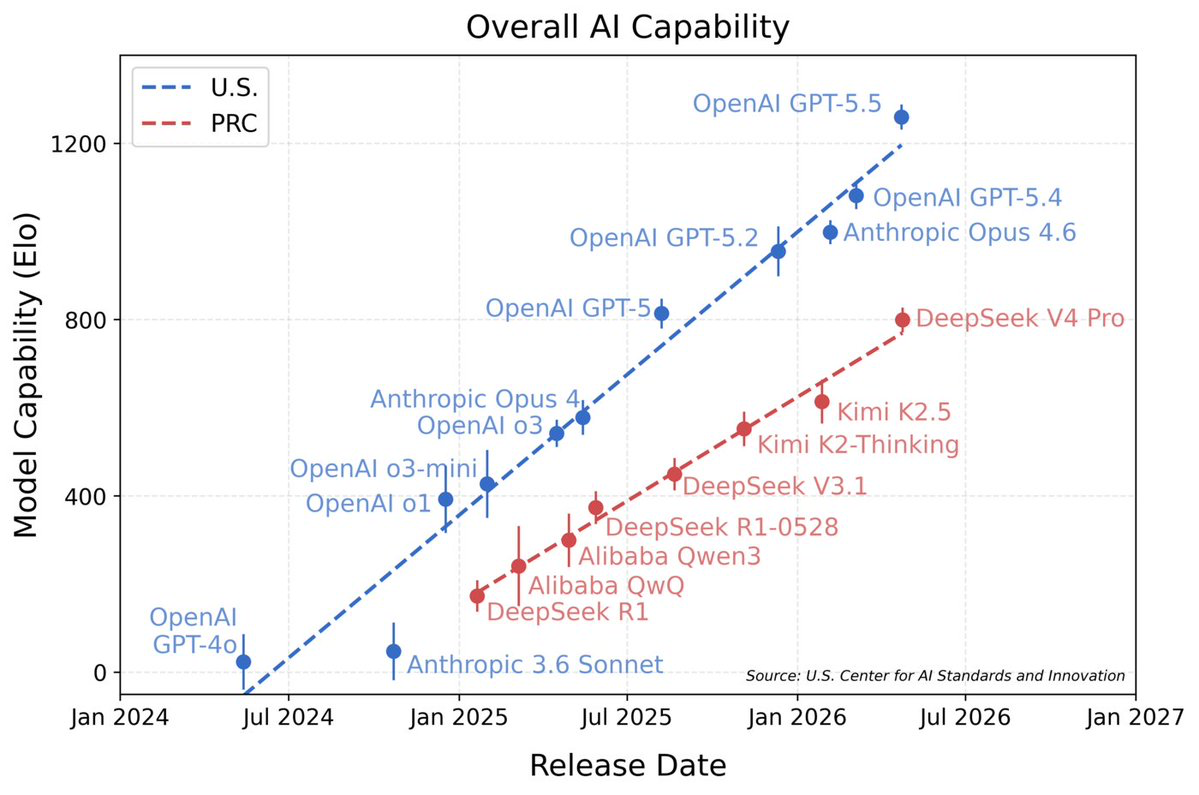
この図で目を引く点が 2 つある。
第一に、オープンモデルは全体としていまだクローズドな最前線に後れを取っている。米国の先頭ラインに乗るモデル(GPT-5.5、GPT-5.4、Anthropic の Opus シリーズ、そして現在のクローズド最前線 SOTA である Claude Fable 5)はすべてクローズドだ。図に載るオープンウェイトモデル(DeepSeek、Qwen、Kimi)は、明らかに低いトレンドラインに位置し、Elo で数百点も後ろにいる。
第二に、そしてより印象的なのは、図にあるオープンモデルがすべて中国製だという点だ。アメリカのオープンモデルはどこにも見当たらない。
そうした背景の中で、アメリカのオープンモデルが GPT-5.5 と同じコーディングエージェントのミニベンチマークのタスクをこなすことは、議論の流れを変える。
もはや問いはこうではない。
オープンモデルは役に立つのか。
より良い問いはこうだ。
どのワークロードがいまもクローズドな最前線モデルを必要とし、どのワークロードが強力なオープンモデルで動かせるようになったのか。
この区別は、実際のプロダクトにとって重要だ。
AI エージェントは単なるチャットボットではない。ファイルを読み、コードを書き換え、ツールを呼び出し、テストを実行し、失敗したステップを再試行し、長いワークフローをまたいで動く。この種の用途では、モデル選択は生の能力だけの話ではない。制御、コスト構造、可用性、そしてモデルを事業に合わせて適応させられるかどうかの問題でもある。
まさにそこで、オープンモデルは戦略的に重要になりつつある。
私たちが検証したアメリカのオープンモデル
このミニベンチマークでのオープンモデルは NVIDIA Nemotron-3 Ultra 550B-A55B だった。
そのモデルの概要は次のとおり。
- 総パラメータ 5500 億
- アクティブパラメータ 550 億
- MoE / latent-MoE 系のアーキテクチャ
- アメリカの AI インフラ企業 NVIDIA が開発
- NVIDIA NIM 経由で期間限定の無料推論、Token Station でも無料提供
これは安いという理由だけで使われる小さなモデルではない。本格的な推論やエージェントのワークロードのために設計された、大型のアメリカ製オープンモデルだ。
GPT-5.5 は依然として先頭を走るクローズドな最前線モデルだ。強力で、洗練され、幅広く役立つ。Anthropic の最新フラッグシップであり、現在のクローズド最前線 SOTA を代表する Claude Fable 5 も同様だ。このミニベンチマークではまだ直接対決の数値はないが、オープンモデルが追いかける基準の一部である。Nemotron-3 Ultra は別種の価値を体現する。モデルの特性がより透明で、デプロイの制御性がより高い、強力なオープンモデルだ。
開発者やビジネスにとって、それは重要だ。
ミニベンチマークの構成
Token Station Arena を使い、コーディングエージェントのミニベンチマークを実行した。小さく的を絞ったテストであり、リーダーボードではない。ランナー、3 つのタスク、すべてのチェックがオープンソースなので、何を検証したかを正確に読み取り、自分で再現できる。
構成は次のとおり。
- 2 つのモデル:GPT-5.5 と NVIDIA Nemotron-3 Ultra 550B-A55B
- 3 つのコーディングエージェントのタスク
- モデルごと・タスクごとに 3 回実行
- 合計 18 回の実行
このミニベンチマークでは、ユニットテスト、型チェック、clippy、タスク固有の検証といった決定論的なチェックを用いた。
これは重要だ。コーディングエージェントは、答えがもっともらしく聞こえるかどうかだけで評価されるべきではないからだ。実際にコードを変更し、チェックをパスする必要がある。
3 つのコーディングエージェントのタスク
3 つのタスクはいずれも Arena リポジトリの benchmark/tasks フォルダにある。各タスクは自己完結した Rust のフィクスチャプロジェクトに、プロンプトと機械的に検証可能な成功基準の一式が付いたものだ。どのタスクも cargo test、cargo check、cargo clippy --all-targets -- -D warnings をすべてパスする必要があり、タスクの許可されたパス以外のファイルを編集した実行はジャッジが不合格にする。そのためエージェントは、無関係な変更やテストの弱体化でパスすることはできない。
1. API エンドポイントを追加する
このタスクは、既存のコードベースの中で通常のプロダクト開発の変更を行えるかどうかを試す。catalog-core ライブラリ crate と catalog-api Axum crate を含む小さな Rust ワークスペースだ。プロンプトはリポジトリから原文のまま引用する。
- Add `GET /products/top?limit=<n>` to the Axum app.
- Return JSON products sorted by descending popularity.
- Respect the optional `limit` query parameter. If it is
missing, return all products.
- Reuse existing catalog-core logic where possible.
- Do not remove or weaken the integration test.エージェントはプロジェクト構造を理解し、正しいルートやハンドラを見つけ、エンドポイントを追加し、期待されるレスポンスを返し、プロジェクトのチェックをパスし続けなければならない。これは開発者が日々こなす類のタスクだ。パズルではない。実務的なエンジニアリング作業だ。
2. 失敗しているテストを修正する
このタスクはデバッグ能力を試す。フィクスチャには catalog-core の壊れた価格計算の実装と、失敗するユニットテストが含まれている。
- Fix the failing pricing unit test in `catalog-core`.
- Preserve the public function names and signatures.
- Keep the implementation simple and idiomatic.
- Do not weaken, remove, or rewrite tests to hide the bug.エージェントは根本原因を特定し、実装を修正し、テスト自体には手を付けずにテストを再び通る状態に戻さなければならない。これが重要なのは、実際のコーディングエージェントは失敗から立ち直る必要があるからだ。すべてが整っていて明白なときにだけ新しいコードを書く、というわけにはいかない。
3. 価格計算ロジックをリファクタリングする
このタスクは、ビジネス上の挙動を変えずにコード構造を改善できるかどうかを試す。
- Refactor the duplicated discount calculation in
`catalog-core/src/pricing.rs`.
- Introduce one shared helper for computing the discount amount.
- Preserve all public function names, signatures, and behavior.
- Do not remove or weaken tests or the custom refactor check.標準のチェックに加えて、このタスクには 4 つ目の関門がある。重複が実際に解消されたかを検証する独自の check-refactor.mjs スクリプトだ。エージェントは価格計算のルールを保ちつつ、ユニットテスト、型チェック、clippy、そしてそのリファクタリング固有の検証をパスしなければならない。これは単純なコード生成のプロンプトよりも、実際の本番エンジニアリングに近い。モデルはコードとビジネスロジックの両方を理解する必要がある。
結果
| 指標 | GPT-5.5 | NVIDIA Nemotron-3 Ultra 550B-A55B |
|---|---|---|
| 完了した実行 | 9/9 | 9/9 |
| ジャッジ平均スコア | 5.0 | 4.8 |
重要な結果はタスクの完遂率だ。
両モデルともすべての実行を完遂した。
これこそが、打ち出すべきシグナルだ。
アメリカのオープンモデルが、GPT-5.5 と同じコーディングエージェントのワークロードを完遂した。
開発者にとって、これは意味のある転換だ。オープンモデルはもはや次善の選択肢ではない。実際のエージェントシステムにとって本命の候補になりつつある。
オープンモデルが追い上げている
より広い AI 市場は、マルチモデルの世界へと向かっている。
クローズドモデルは依然として重要だ。最前線を切り開くことが多く、価値の高い多くのタスクにとって優れた選択肢であり続ける。
だがオープンモデルは急速に追い上げている。実用的なコーディングや推論、エージェントのワークフローに十分な能力を備えつつある。さらに、クローズドモデルが常に提供できるとは限らない利点もある。
- デプロイ戦略をより制御できる
- プライベートや社内のワークフローに適している
- 長期的なインフラ計画がより見通せる
- カスタマイズの自由度が高い
- 単一のクローズドな提供元への依存が少ない
Nemotron-3 Ultra がとりわけ重要なのは、それが NVIDIA によるアメリカのオープンモデルだからだ。AI の能力とインフラの制御の両方を重視する企業にとって、この組み合わせは戦略的に意味を持つ。
これが Token Station にとって意味すること
未来は、あらゆるタスクに一つのモデル、ではない。
クローズドな最前線モデルを必要とするワークロードもある。強力なオープンモデルで動かせるようになったワークロードもある。多くのチームは、本番で何を使うかを決める前に、両方を試したいと考えるだろう。
だからこそ Token Station(models.bytefuture.ai)が存在する。
Token Station を使えば、開発者は Nemotron-3 Ultra や GPT-5.5 など、最前線のモデルに一つのプラットフォームからアクセスできる。ブランド名や思い込みで選ぶのではなく、自分のワークロードでモデルを比較できる。
狙いは、唯一絶対の勝者を宣言することではない。
狙いは、モデル選択を実践的なものにすることだ。
自分で実行してみる
アメリカのオープンモデルは、クローズドな最前線モデルに追いついてきている。
Nemotron-3 Ultra が私たちのコーディングエージェントのミニベンチマークで GPT-5.5 と肩を並べたことは、モデルの勢力図が変わりつつあることを示すもう一つの兆しだ。
しかも、私たちの言葉をうのみにする必要はない。ミニベンチマーク一式は Anthropic 互換のゲートウェイなら何にでも対して走るので、Token Station のキーと、PATH に通した claude CLI があれば、私たちの実行を再現するのに必要なのは 4 つのコマンドだ。
git clone https://github.com/hydai/token-station-arena
cd token-station-arena
point the runner at Token Station (gateway root, no /v1)
export ANTHROPIC_BASE_URL=https://models.bytefuture.ai
export ANTHROPIC_AUTH_TOKEN=<your Token Station API key>
run all three tasks against the configured models
cargo run –release – benchmark –tasks all –models all –runs 3
ランナーは各タスクを隔離されたフィクスチャ内で実行し、決定論的なチェックを適用し、実行ごとのトークン数・コスト・所要時間を記した Markdown レポートを生成する。benchmark/tasks/ に自分のタスク(フィクスチャ、prompt.md、task.yml)を置けば、私たちのコードではなくあなたのコードでこれらのモデルがどう振る舞うかを確かめられる。
Token Station で Nemotron-3 Ultra(NVIDIA NIM 提供により期間限定で無料)を、GPT-5.5 や Claude Fable 5、その他の最前線モデルと並べて試してみてほしい。